NodeJS
NodeJS基础知识
一、dos命令
d: 切换到D盘
dir 查看当前目录下的文件
cd 目录名 切换工作目录
dir /s 查看文件夹下的所有内容包括自子文件夹内的内容
cd .. 返回上层目录
ctrl+c 终止命令
二、Nodejs环境与浏览器环境的区别
在nodejs环境中无法使用DOM,BOM,AJAX,........
nodejs中的顶级对象为global,也可以用globalThis访问顶级对象。
浏览器中的顶层对象是window。
三、Node.js介绍
Node.js 是一种基于 V8 引擎的 JavaScript 运行时,它使得开发者可以使用 JavaScript 来编写服务器端代码。由于 Node.js 提供了许多服务器端相关的功能和接口,因此它通常被归类为一种后端技术。虽然 Node.js 本身也是使用 JavaScript 编写的,因此一些开发者也将其归类为前端技术,但实际上,它的主要用途还是在于服务器端的开发。此外,尽管 Node.js 不是一种后端语言,但它可以让 JavaScript(前端的语言)在服务器上运行,从而实现后端开发的技术。
Node.js是一个基于Chrome V8 引擎的 JavaScript 运行环境。Node.js使用了一个事件驱动、非阻塞式 I/O模型,使其轻量又高效。Node.js的包管理器npm,是全球最大的开源生态系统。
作用:
统一前后端编程语言环境为JavaScript
带来高性能的 I/O 操作
并行 I/O 可以更高效的利用分布式环境
并行 I/O 提高 Web 渲染能力
可用于云计算平台
可用于游戏开发
工具类应用
1.Buffer
一、概念
Buffer 是一个类似于数组的 对象 ,用于表示固定长度的字节序列
Buffer 本质是一段内存空间,专门用来处理 二进制数据 。

二、特点
- Buffer 大小固定且无法调整
- Buffer 性能较好,可以直接对计算机内存进行操作
- 每个元素的大小为 1 字节(byte)=8比特

三、使用
3.1创建Buffer
3.1.1Buffer.alloc(n)
创建了一个长度为 n字节的 Buffer,相当于申请了 n 字节的内存空间,每个字节的值为 0
let buf = Buffer.alloc(10);//创建一个10字节的buffer
console.log(buf); //<Buffer 00 00 00 00 00 00 00 00 00 00>3.1.2Buffer.allocUnsafe(n)
速度比alloc更快,创建了一个长度为 n字节的 Buffer,但可能存在旧的数据, 可能会影响执行结果,所以叫unsafe
let buf_2 = Buffer.allocUnsafe(10);
// 创建的buffer可能会包含旧的内存空间的数据
console.log(buf_2);//<Buffer 00 01 00 22 00 00 00 00 00 00>3.1.3Buffer.from(arr/str)
通过字符串/数组创建 Buffer
let buf_3 = Buffer.from("hello"); //一个英文字母占1个字节
let buf_4 = Buffer.from("你好"); // 中文汉字占3个字节
let buf_5 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]);
console.log(buf_3); //<Buffer 68 65 6c 6c 6f> 十六进制
console.log(buf_4); //<Buffer e4 bd a0 e5 a5 bd>
console.log(buf_5); //<Buffer 69 6c 6f 76 65 79 6f 75>3.2 Buffer 与字符串的转化
我们可以借助 toString 方法将 Buffer 转为字符串
let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]);
console.log(buf_4.toString()); // iloveyoutoString 默认是按照 utf-8 编码方式进行转换的。即toStrong('utf-8');
3.3 Buffer 的读写
Buffer 类似于数组,可以直接通过 [] 的方式对数据进行处理。
let buf = Buffer.from("hello world");
console.log(buf); // <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>十六进制
// 对buffer内的单个元素进行读取
console.log(buf[0]); // 104 十进制
console.log(buf[0].toString(2)); // 01101000 二进制
// 对buffer内的单个元素进行修改
buf[0] = 95;
console.log(buf); //<Buffer 5f 65 6c 6c 6f 20 77 6f 72 6c 64> 十六进制
console.log(buf.toString()); //_ello world3.4 Buffer补充
3.4.1溢出
buffer使用二进制进行存储,最大存储值为255,输出使用十六进制
let buf = Buffer.from("hello");
buf[0] = 361; // 大于255,溢出,舍弃高位8位的数字
console.log(buf); // <Buffer 69 65 6c 6c 6f>3.4.2中文
utf-8编码,一个中文占3个字节
let buf_1 = Buffer.from("你好");
console.log(buf_1);// <Buffer e4 bd a0 e5 a5 bd> 占6个字节2.fs模块
fs 全称为 file system ,称之为 文件系统 ,是 Node.js 中的 内置模块 ,可以对计算机中的磁盘进行操作。
一、文件写入
文件写入就是将 数据 保存到 文件 中,我们可以使用如下几个方法来实现该效果
| 方法 | 说明 |
|---|---|
| writeFile | 异步写入 |
| writeFileSync | 同步写入 |
| appendFile / appendFileSync | 追加写入 |
| createWriteStream | 流式写入 |
1.1writeFile 异步写入
语法: fs.writeFile(file, data[, options], callback)
参数说明:
- file 文件名
- data 待写入的数据
- options 选项设置 (可选)
- callback 写入回调
返回值: undefined
异步:异步写入的回调函数会等待文件的读写操作完成后再执行,期间程序可以继续执行下面的代码。
代码示例:
/*
需求:
新建一个文件,座右铭.txt,写入内容为:三人行,则必有我老师
*/
// 1.导入fs模块
const fs = require("fs");
// 2.写入文件 文件如果不存在会自动创建并写入
fs.writeFile("./座右铭.txt", "三人行,则必有我老师", (err) => {
// 错误优先函数
if (err) {
console.log(err); // 如果写入失败,err值为错误对象
return;
} else { // 如果写入成功,err值为null
console.log("写入成功");
}
});
// 下面代码会先于上面的回调函数执行,因为是同步的,而上面回调函数是异步的要等文件写入操作完成后再执行
console.log(1 + 1);1.2writeFileSync 同步写入
语法: fs.writeFileSync(file, data[, options])
参数与 fs.writeFile 大体一致,只是没有 callback 参数
返回值: undefined
同步:无回调函数,该读写操作后面的代码要等待读写操作完成后再执行。
代码示例:
try{ // 进行错误处理
fs.writeFileSync('./座右铭.txt', '三人行,必有我师焉。');
}catch(e){ // ES6异常处理
console.log(e); // 写入错误时执行的代码
}Node.js 中的磁盘操作是由其他 线程 完成的,结果的处理有两种模式:
- 同步处理 JavaScript 主线程 会等待 其他线程的执行结果,然后再继续执行主线程的代码, 效率较低
- 异步处理 JavaScript 主线程 不会等待 其他线程的执行结果,直接执行后续的主线程代码, 效率较好
1.3appendFile / appendFileSync 追加写入
appendFile 作用是在文件尾部追加内容,appendFile 语法与 writeFile 语法完全相同
语法:
fs.appendFile(file, data[, options], callback)
fs.appendFileSync(file, data[, options])返回值: 二者都为 undefined
示例代码:
// 1.引入fs模块
const fs = require("fs");
// 2.调用 appendFile()方法 往座右铭.txt内追加内容
fs.appendFile("./座右铭.txt", ",可以为师也", (err) => {
if (err) {
console.log("写入失败");
return; // 写入失败return结束回调函数
}
console.log("追加写入成功");
});
// 3.调用 appendFileSync()方法 同步写入
fs.appendFileSync("./座右铭.txt", "。\r\n三人行,必有我师焉");
// \r\n是换行符,\r是回车符,\n是换行符,\r\n是回车换行符。
// 4.使用 writeFile 通过配置参数{flag:'a'} 实现文件追加写入 a:追加
fs.writeFile("./座右铭.txt", "hi,hi", { flag: "a" }, (err) => {
if (err) {
console.log("写入失败");
return;
}
console.log("写入成功");
});1.4createWriteStream 流式写入
语法: fs.createWriteStream(path[, options])
参数说明:
- path 文件路径
- options 选项配置( 可选 )
返回值: Object
代码示例:
/*
* 将诗的内容写入观书有感.txt文件中
*/
// 1.导入fs模块
const fs = require("fs");
// 2.创建写入流对象
const ws = fs.createWriteStream("./观书有感.txt");
// write 写入内容
ws.write("半亩方塘一鉴开\r\n"); // \r\n换行
ws.write("天光云影共徘徊\r\n");
ws.write("问渠哪得清如许\r\n");
ws.write("为有源头活水来\r\n");
// 关闭通道
ws.close(); // 可选,在全部写入完毕后会自动关闭注意:
程序打开一个文件是需要消耗资源的 ,流式写入可以减少打开关闭文件的次数。
流式写入方式适用于 大文件写入或者频繁写入 的场景, writeFile 适合于 写入频率较低的场景。
1.5文件写入场景
文件写入 在计算机中是一个非常常见的操作,下面的场景都用到了文件写入
- 下载文件
- 安装软件
- 保存程序日志,如 Git
- 编辑器保存文件
- 视频录制
当 需要持久化保存数据 的时候,应该想到 文件写入
二、文件读取
文件读取顾名思义,就是通过程序从文件中取出其中的数据,我们可以使用如下几种方式:
| 方法 | 说明 |
|---|---|
| readFile | 异步读取 |
| readFileSync | 同步读取 |
| createReadStream | 流式读取 |
2.1readFile异步读取
语法: fs.readFile(path[, options], callback)
参数说明:
- path 文件路径
- options 选项配置
- callback 回调函数
返回值: undefined
代码示例:
/*
需求:读取观书有感.txt 并输出到控制台
*/
// 1.引入fs模块
const fs = require("fs");
// 2.异步读取
fs.readFile("./观书有感.txt", (err, data) => {
// 错误优先回调函数
// err:返回错误信息,data:读取到的文件内容为一个Buffer
if (err) {
console.log("读取出错");
return;
}
// console.log(data);//<Buffer e5 8d 8a e4 ba a9 e6 96 b9 e5 a1 98 e4 b8 80 e9 89 b4 e5 bc 80 0d 0a e5 a4 a9 e5 85 89 e4 ba 91 e5 bd b1 e5 85 b1 e5 be 98 e5 be 8a 0d 0a e9 97 ae e6 ... 42 more bytes>
console.log(data.toString()); // 读取成功
});2.2readFileSync同步读取
语法: fs.readFileSync(path[, options])
参数说明:
- path 文件路径
- options 选项配置
返回值: string | Buffer
代码示例:
let data = fs.readFileSync("./观书有感.txt"); // 读取文件内容存储到data中
console.log(data.toString()); // 将读取到的buffer转换为字符2.3 createReadStream 流式读取
语法: fs.createReadStream(path[, options])
参数说明:
- path 文件路径
- options 选项配置( 可选 )
返回值: Object
代码示例:
// 1.引入fs模块
const fs = require("fs");
// 2.创建读取流对象
const rs = fs.createReadStream("./data.txt");
// 3.为rs对象绑定data事件 获取读取到的数据,每次取出 64k 数据后执行一次 data 回调
rs.on("data", (chunk) => {
console.log(chunk.length); // 65536字节 =>64KB
});
// 4.end 读取完毕后, 执行 end 回调 (可选事件)
rs.on('end',()=>{
console.log('读取完毕')
})2.4读取文件应用场景
- 电脑开机
- 程序运行
- 编辑器打开文件
- 查看图片
- 播放视频
- 播放音乐
- Git 查看日志
- 上传文件
- 查看聊天记录
2.5fs练习-复制文件
需求:
复制[资料]文件夹下的[笑看风云.mp4]
2.5.1方式一:文件读取
使用readFile + writeFile
// 引入fs模块
const fs = require('fs');
// 读取文件的所有内容
let data = fs.readFileSync('./资料/笑看风云.mp4');
// 将读取到的内容写入文件中
fs.writeFileSync('./资料/笑看风云2.mp4',data);
// 查看内存占用
const process = require("process");
console.log(process.memoryUsage()); // rss 110710784字节 105MB缺陷:fs.readFileSync会将文件的全部内容一次全部读取完毕,若文件较大,占用的内存会较大。
5.2.2方式二:使用流式读取
使用 creatReadStream + createWriteStream
// 引入fs模块
const fs = require('fs');
// 创建读取流对象
let rs = fs.createReadStream('./资料/笑看风云.mp4');
// 创建写入流对象
let ws = fs.createWriteStream('./资料/笑看风云3.mp4');
// 绑定data事件 进行文件读取
rs.on('data',(chunk)=>{ // 理想情况下每次只读取64字节的数据
// 将每次读取到的数据写入
ws.write(chunk);
});
// 查看内存占用
const process = require("process");
// end 事件 表示读取完毕
rs.on("end", () => {
console.log("读取完成");
ws.
console.log(process.memoryUsage()); // 查看内存占用
// rss 43106304 => 40.7MB
});优势:占用内存比直接全部读取的要少。
5.2.3方式三:使用管道流
rs.pipe(ws);
// 引入fs模块
const fs = require('fs');
// 创建读取流对象
let rs = fs.createReadStream('./资料/笑看风云.mp4');
// 创建写入流对象
let ws = fs.createWriteStream('./资料/笑看风云3.mp4');
// 管道流 将读取到的数据通过管道输送到可写流中
rs.pipe(ws);三、文件移动与重命名
在 Node.js 中,我们可以使用 rename 或 renameSync 来移动或重命名 文件或文件夹
重命名和移动文件的 本质 就是更改文件的路径和文件名
语法:
fs.rename(oldPath, newPath, callback)
fs.renameSync(oldPath, newPath)
参数说明:
- oldPath 文件当前的路径
- newPath 文件新的路径
- callback 操作后的回调
代码示例:
// 1.导入fs模块
const fs = require("fs");
// 2.调用rename方法
fs.rename("./座右铭.txt", "./论语.txt", (err) => {
if (err) {
console.log("操作失败!");
return;
}
console.log("重命名成功");
});
// 2.文件的移动
fs.rename("./data.txt", "./资料/data.txt", (err) => {
if (err) {
console.log("移动失败");
return;
}
console.log("移动成功");
});四、文件删除
在 Node.js 中,我们可以使用 unlink 、unlinkSync 或 rm、rmSync 来删除文件
语法:
fs.unlink(path, callback)
fs.unlinkSync(path)
fs.rm(path,callback)
fs.rmSync(path)
参数说明:
- path 文件路径
- callback 操作后的回调
代码示例:
// 1.导入fs模块
const fs = require("fs");
// 2.调用 unlink 方法删除文件 unlinkSync 同步
fs.unlink("./观书有感.txt", (err) => {
if (err) {
console.log("删除失败");
return;
}
console.log("删除成功");
});
// 3.使用 rm 方法删除文件 nodeJS 14.4 rmSync 同步
fs.rm("./论语.txt", (err) => {
if (err) {
console.log("删除失败");
return;
}
console.log("删除成功");
});五、文件夹操作
借助 Node.js 的能力,我们可以对文件夹进行 创建 、 读取 、 删除 等操作
| 方法 | 说明 |
|---|---|
| mkdir / mkdirSync | 创建文件夹 |
| readdir / readdirSync | 读取文件夹 |
| rmdir / rmdirSync | 删除文件夹 |
| rm/rmSync | 删除文件/文件夹 |
5.1 mkdir 创建文件夹
在 Node.js 中,我们可以使用 mkdir 或 mkdirSync 来创建文件夹
语法:
fs.mkdir(path[, options], callback)
fs.mkdirSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
// 1.导入fs模块
const fs = require("fs");
// 2.创建文件夹
fs.mkdir("./html", (err) => {
if (err) {
console.log("创建失败");
return;
}
console.log("创建成功");
});
// 3.递归创建文件夹 recursive:递归
fs.mkdir("./a/b/c", { recursive: true }, (err) => {
if (err) {
console.log("创建失败");
return;
}
console.log("创建成功");
});5.2readdir 读取文件夹
在 Node.js 中,我们可以使用 readdir 或 readdirSync 来读取文件夹 语法:
fs.readdir(path[, options], callback)
fs.readdirSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
// 1.导入fs模块
const fs = require("fs");
// 2.异步读取
fs.readdir("./资料", (err, data) => {
if (err) {
console.log("读取失败");
return;
}
console.log(data); //[ 'data.txt', '笑看风云.mp4', '笑看风云2.mp4', '笑看风云3.mp4' ]
});
//同步读取
let data = fs.readdirSync('./论语');
console.log(data);5.3rmdir 删除文件夹
在 Node.js 中,我们可以使用 rmdir 或 rmdirSync 来删除文件夹 (不建议使用)
建议使用:rm 或 rmSync 方法进行删除文件夹
语法:
fs.rmdir(path[, options], callback)
fs.rmdirSync(path[, options])
fs.rm(path[, options], callback)
fs.rm(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
// 1.导入fs模块
const fs = require("fs");
// 2删除文件夹
fs.rmdir('./html',err =>{
if(err){
console.log('删除失败');
return;
}
console.log('删除成功');
});
// 3递归删除文件夹 使用{ recursive: true }参数进行递归删除
fs.rmdir("./a", { recursive: true }, (err) => {
if (err) {
console.log(err); // 直接删除父文件夹会报错Error:directory not empty
return;
}
console.log("删除成功");
});
// 4.使用rm方法进行删除文件夹
fs.rm("./a", { recursive: true }, (err) => {
if (err) {
console.log(err); // 直接删除父文件夹会报错Error:directory not empty
return;
}
console.log("删除成功");
});六、查看资源状态
在 Node.js 中,我们可以使用 stat 或 statSync 来查看资源的详细信息
语法:
fs.stat(path[, options], callback)
fs.statSync(path[, options])
参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
示例代码:
// 1.导入fs模块
const fs = require("fs");
// 2.stat方法 查看文件状态
fs.stat("./资料/笑看风云.mp4", (err, data) => {
if (err) {
console.log("操作失败");
return;
}
console.log(data);
/* Stats {
size: 81592438, // 文件大小
mtime: 2022-12-05T07:04:31.808Z, // 最后修改时间
birthtime: 2023-03-08T15:31:03.898Z // 创建时间
} */
// 查看资源是否是一个文件
console.log(data.isFile()); // true
// 查看资源是否是一个目录
console.log(data.isDirectory()); // false
});结果值对象结构:
- size 文件体积
- birthtime 创建时间
- mtime 最后修改时间
- isFile 检测是否为文件
- isDirectory 检测是否为文件夹
七、相对路径问题
fs 模块对资源进行操作时,路径的写法有两种:
- 相对路径
- ./座右铭.txt 当前目录下的座右铭.txt
- 座右铭.txt 等效于上面的写法
- ../座右铭.txt 当前目录的上一级目录中的座右铭.txt
- 绝对路径
- D:/Program Files windows 系统下的绝对路径
- /usr/bin Linux 系统下的绝对路径 eg:D:user/bin
相对路径中所谓的 当前目录 ,指的是 命令行的工作目录 ,而并非是文件的所在目录
所以当命令行的工作目录与文件所在目录不一致时,会出现一些 BUG
八、__ dirname __ filename
__ dirname 与 require 类似,都是 Node.js 环境中的'全局'变量
__ dirname 保存着 当前文件所在目录的绝对路径 ,可以使用 __ dirname 与文件名拼接成绝对路径
__ filename 保存着 当前文件的绝对路径
代码示例:
let data = fs.readFileSync(__dirname + '/data.txt');
console.log(data);使用 fs 模块的时候,尽量使用 __dirname 将路径转化为绝对路径,这样可以避免相对路径产生的 Bug
九、批量重命名
将 ./资料/code文件夹下的n.xtxt文件名重命为0n.txt
// 导入fs模块
const fs = require("fs");
// 读取 code 文件夹
const files = fs.readdirSync("./资料/code");
console.log(files); // [ 'data.txt', '笑看风云.mp4', '笑看风云2.mp4', '笑看风云3.mp4' ]
// 遍历files数组
files.forEach((item) => {
// 拆分文件名
let data = item.split("."); // 拆分
let [num, name] = data; // 解构赋值
// 判断
console.log(num, name);
if (Number(num) < 10) {
num = "0" + num;
}
// 创建新到的文件名
let newName = num + "." + name;
console.log(newName);
// 重命名
fs.renameSync(`./资料/code/${item}`, `./资料/code/${newName}`);
});3.path 模块
path 模块提供了 操作路径 的功能,我们将介绍如下几个较为常用的几个 API:
| API | 说明 |
|---|---|
| path.resolve | 拼接规范的绝对路径 常用 |
| path.sep | 获取操作系统的路径分隔符 |
| path.parse | 解析路径并返回对象 |
| path.basename | 获取路径的基础名称 |
| path.dirname | 获取路径的目录名 |
| path.extname | 获得路径的扩展名 |
代码示例:
// 导入fs模块
const fs = require("fs");
// 导入path模块
const path = require("path");
// 写入文件
// fs.writeFileSync(__dirname+'/index.html');
console.log(__dirname + "./index.html");
//D:\front_end\NodeJS\03 path模块./index.html 路径名不规范
// resolve
console.log(path.resolve(__dirname, "./index.html"));
//D:\front_end\NodeJS\03 path模块\index.html 拼接规范的绝对路径
// sep 路径分隔符
console.log(path.sep);
// windows \ linux /
// parse() 解析 __filename:文件的绝对路径
console.log(__filename); // D:\front_end\NodeJS\03 path模块\path.js
console.log(path.parse(__filename));
/*
{
root: 'D:\\', 盘符
dir: 'D:\\front_end\\NodeJS\\03 path模块',
base: 'path.js', 文件名
ext: '.js', 扩展名
name: 'path' 文件名
}
*/
// basename 获取文件名
console.log(path.basename(__filename)); // path.js
// dirname 获取文件夹名
console.log(path.dirname(__filename)); //D:\front_end\NodeJS\03 path模块
// extname 获取文件扩展名
console.log(path.extname(__filename)); //.js4.HTTP 协议
一、概念
HTTP(hypertext transport protocol)协议;中文叫超文本传输协议
是一种基于TCP/IP的应用层通信协议
这个协议详细规定了 浏览器 和万维网 服务器 之间互相通信的规则。
协议中主要规定了两个方面的内容
- 客户端:用来向服务器发送数据,可以被称之为请求报文
- 服务端:向客户端返回数据,可以被称之为响应报文
报文:可以简单理解为就是一堆字符串
二、请求报文的组成
- 请求行
- 请求头
- 空行
- 请求体
三、HTTP 的请求行
GET https://baidu.com:80/index.html?a=100&b=200#logo / HTTP/1.1
请求方法(get、post、put、delete等)
方法 作用 GET 主要用于获取数据 POST 主要用于新增数据 PUT/PATCH 主要用于更新数据 DELETE 主要用于删除数据 请求 URL(统一资源定位符)
例如:http://www.baidu.com:80/index.html?a=100&b=200#logo
- http: 协议(https、ftp、ssh等)
- www.baidu.com 域名 也可以为IP地址
- 80 端口号 (http默认80 https默认443)
- /index.html 路径
- a=100&b=200 查询字符串
- #logo 哈希(锚点链接)
HTTP协议版本号
四、HTTP 请求头
格式:『头名:头值』
常见的请求头有:
| 请求头 | 解释 |
|---|---|
| Host | 主机名 |
| Connection | 连接的设置 keep-alive(保持连接);close(关闭连接) |
| Cache-Control | 缓存控制 max-age = 0 (没有缓存) |
| Upgrade-Insecure-Requests | 将网页中的http请求转化为https请求(很少用)老网站升级 |
| User-Agent | 用户代理,客户端字符串标识,服务器可以通过这个标识来识别这个请求来自 哪个客户端 ,一般在PC端和手机端的区分 |
| Accept | 设置浏览器接收的数据类型 |
| Accept-Encoding | 设置接收的压缩方式 |
| AcceptLanguage | 设置接收的语言 q=0.7 为喜好系数,满分为1 |
| Cookie | 后面单独讲 |
五、HTTP 的请求体
请求体内容的格式是非常灵活的,
(可以是空)==> GET请求,
(也可以是字符串,还可以是JSON)===> POST请求
六、响应报文的组成
- 响应行
HTTP/1.1 200 OK HTTP/1.1:HTTP协议版本号
200:响应状态码
200:请求成功 404:找不到资源 403:禁止请求 500 :服务器内部错误
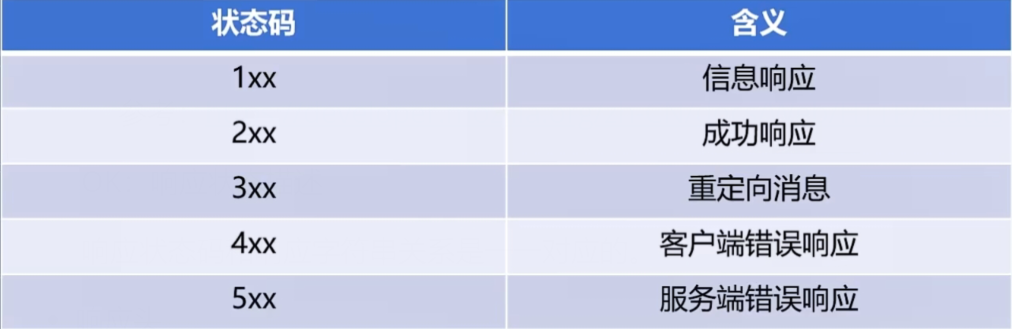
OK:响应状态描述
200:OK 403:Forbidden 404:Not Found 500:Internal Server Error
参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
响应状态码和响应字符串关系是一一对应的。
- 响应头
Cache-Control:缓存控制 private 私有的,只允许客户端缓存数据
Connection 链接设置
Content-Type:text/html;charset=utf-8 设置响应体的数据类型以及字符集,响应体为html,字符集
utf-8
Content-Length:响应体的长度,单位为字节
"Access-Control-Allow-Origin", "*" 设置跨域空行
响应体
响应体内容的类型是非常灵活的,常见的类型有 HTML、CSS、JS、图片、JSON
七、网络基础概念
7.1 IP介绍
IP 也称为 IP地址,本身是一个数字标识,
例如:192.168.1.3
由32位的二进制数字组成。

7.2 IP的作用
IP用于标识网络中的设备,实现设备间的通信
7.3 IP的分类
IP地址由32位的二进制数字组成,即32Bit,4字节,
一共可以标识4294967296个IP地址
广域网 IP (公网IP)
局域网 IP (私网IP)
本地回环 IP 地址 127.0.0.1 ~ 127.255.255.254
7.4 端口
应用程序的数字标识
一台现代计算机有65536个端口(0 ~ 65535)
一个应用程序可以使用一个或多个端口
7.5 端口的作用
实现不同主机应用程序之间的通信
根据端口能识别到主机上的不同的应用程序
八、创建 HTTP 服务
使用 nodejs 创建 HTTP 服务
8.1 操作步骤
// 1.导入http模块
const http = require("http");
// 2.创建服务对象
const server = http.createServer((request, response) => {
response.end("hello HTTP Server"); // 设置响应体并结束响应
});
// 3.监听端口,启动服务
server.listen(9000, () => {
console.log("服务在9000端口启动");
});http.createServer 里的回调函数的执行时机: 当接收到 HTTP 请求的时候,就会执行
8.2 测试
浏览器请求对应端口
http://127.0.0.1:90008.3 注意事项
命令行 ctrl + c 停止服务
当服务启动后,更新代码 必须重启服务才能生效,可以使用nodemon进行热更新
响应体中 中文乱码解决办法
jsresponse.setHeader("content-type", "text/html;charset=utf-8");端口号被占用
Error: listen EADDRINUSE: address already in use :::9000解决办法:
- 关闭当前正在运行监听端口的服务 ( 使用较多 )
- 修改其他端口号
HTTP协议默认端口是80,HTTPS 协议的默认端口是443,HTTP服务开发常用端口有 3000,8080,8090,9000 等
如果端口被其它程序占用,可以使用资源监视器找到占用端口的程序的PID,任何使用任务管理器关闭对应的程序。
九、浏览器查看 HTTP 报文
点击步骤
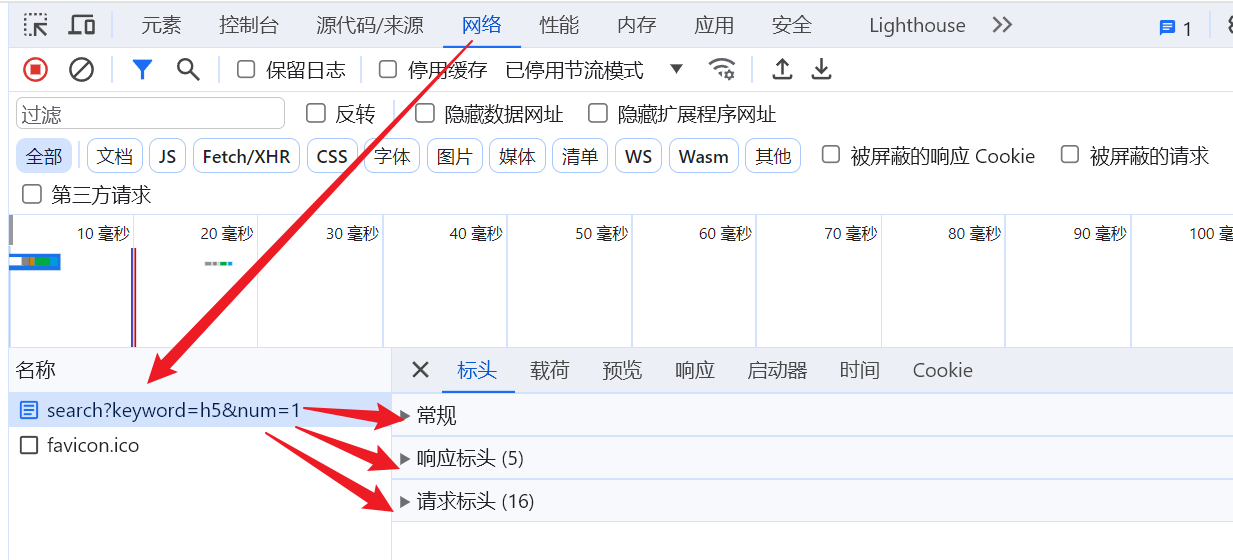
9.1 查看请求行与请求头
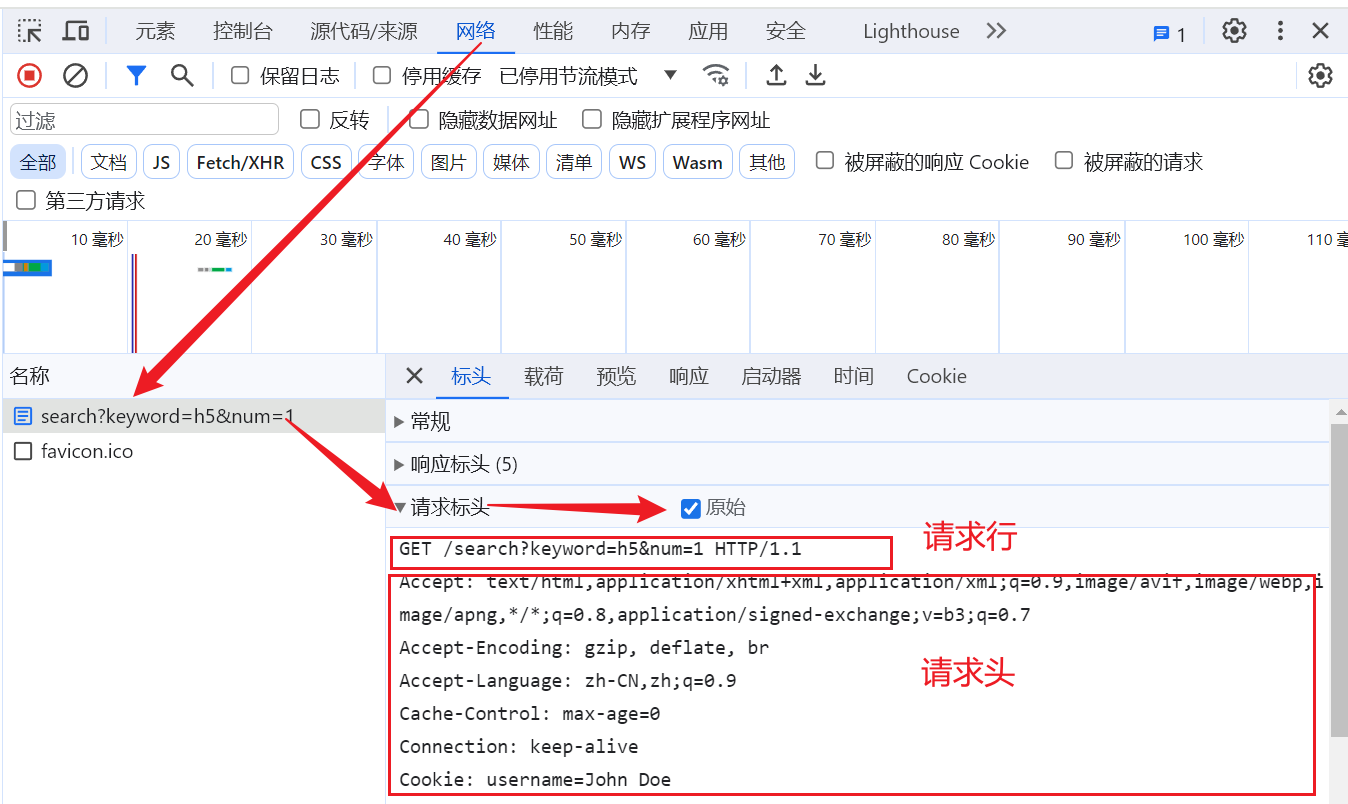
9.2 查看请求体
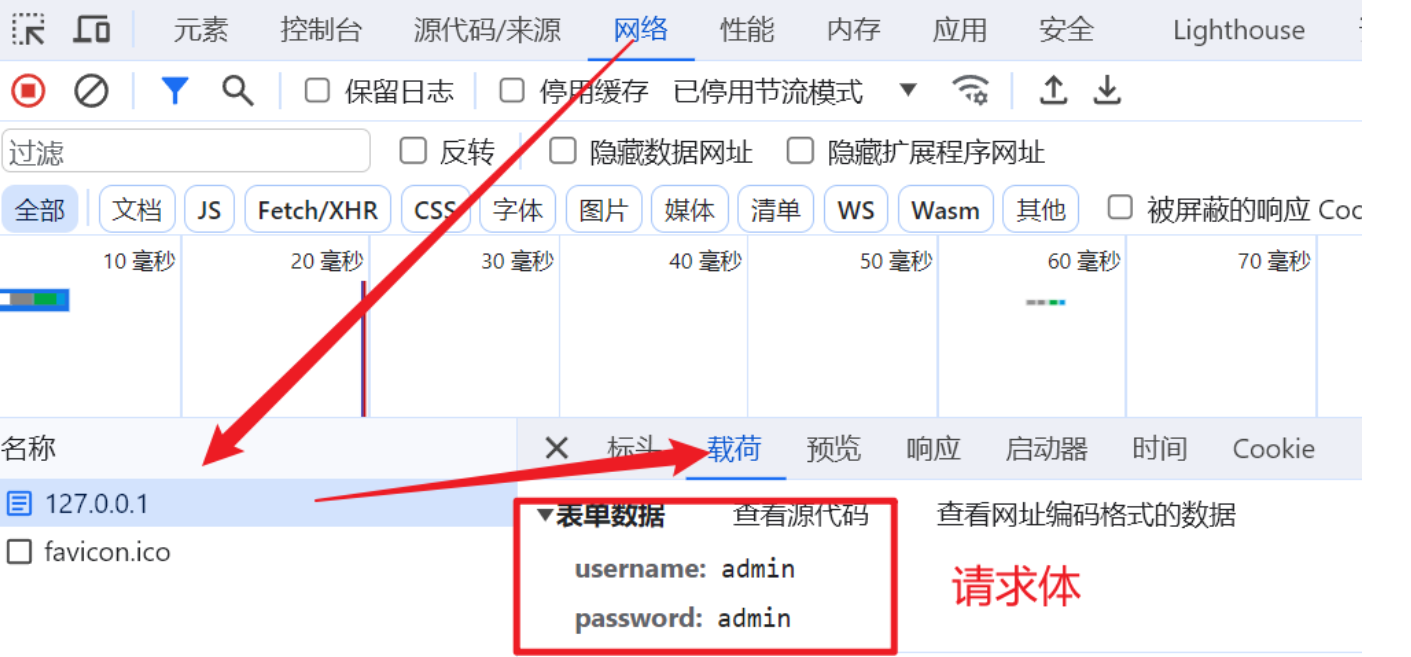
9.3 查看 URL 查询字符串
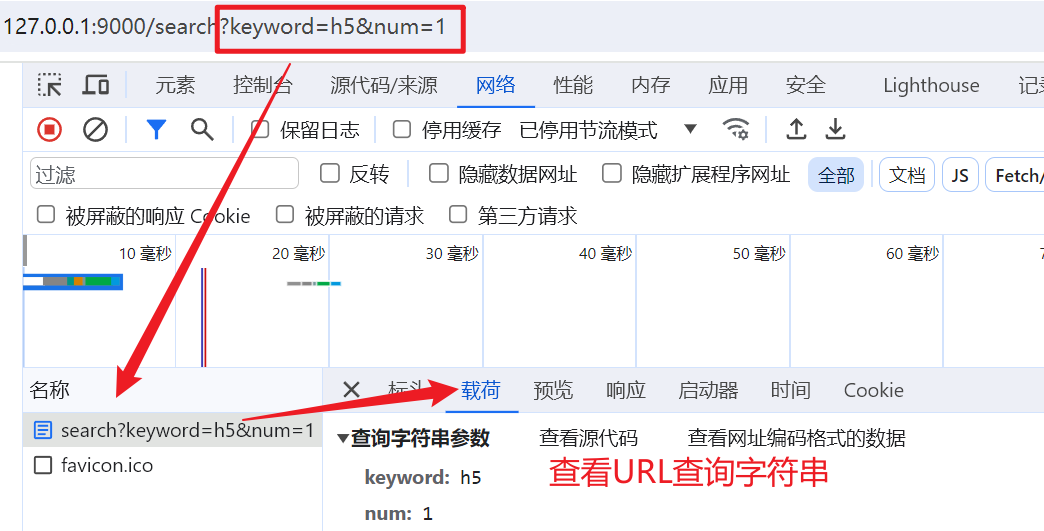
9.4 查看响应行与响应头
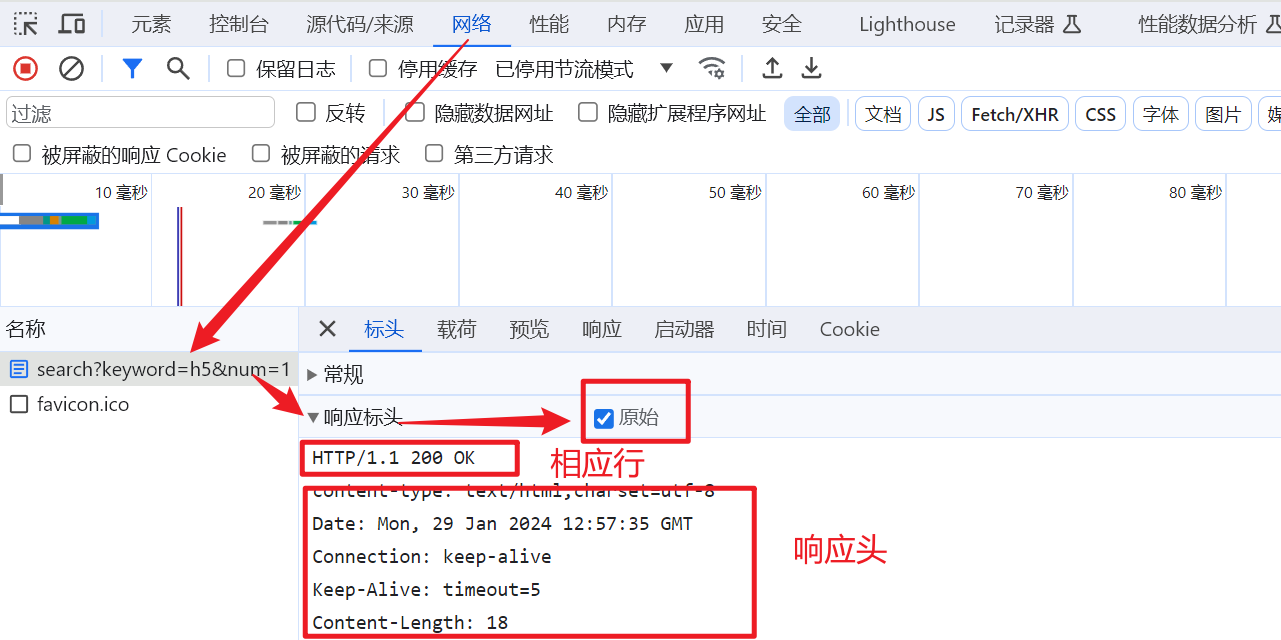
9.5 查看响应体
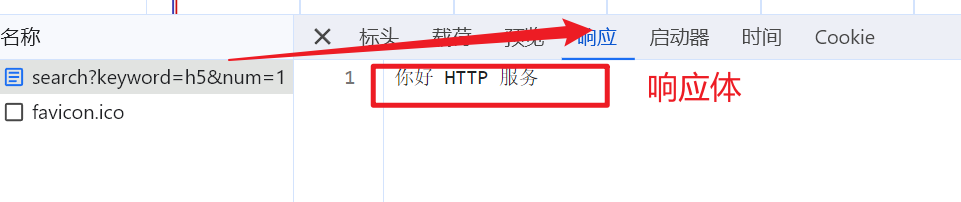
十、获取 HTTP 请求报文
想要获取请求的数据,需要通过 request 对象
| 含义 | 语法 | 重点掌握 |
|---|---|---|
| 请求方法 | request.method | * |
| 请求版本 | request.httpVersion | |
| 请求路径 | request.url | * |
| URL 路径 | require('url').parse(request.url).pathname | * |
| URL 查询字符串 | require('url').parse(request.url, true).query | * |
| 请求头 | request.headers | * |
| 请求体 | request.on('data', function(chunk){}) request.on('end', function(){}); |
注意事项:
- request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容
- request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』
- 关于路径:如果访问网站的时候,只填写了 IP 地址或者是域名信息,此时请求的路径为『 / 』
- 关于 favicon.ico:这个请求是属于浏览器自动发送的请求
10.1提取http报文:
// 导入http模块
const http = require("http");
// 导入url模块
const url = require('url');
// 创建服务对象
const server = http.createServer((request, response) => {
// 获取请求的方法
console.log(request.method);
// 获取请求的url 只包含url 中的路径与查询字符串
console.log(request.url);
// 获取http协议的版本号
console.log(request.httpVersion);
// 获取http的请求头
console.log(request.headers);
// 获取请求头内的指定内容
console.log(request.headers.host);
console.log(request.url);
// 3.监听端口,启动服务
server.listen(9000, () => {
console.log("服务在9000端口启动");
});10.2提取HTTP报文中url的路径与查询字符串
- 方法一:使用url模块中的的parse方法进行解析
// 导入http模块
const http = require("http");
// 1.导入url模块
const url = require('url');
// 创建服务对象
const server = http.createServer((request, response) => {
// 2.解析 request.url
console.log(request.url); // 路径+查询字符串
// 获取url中的查询字符串
let res = url.parse(request.url,true) // true:将query解析成一个对象默认字符串
console.log(res);
/* Url {
search: '?keyword=h5&num=1',
query: [Object: null prototype] { keyword: 'h5', num: '1' },
pathname: '/search',
path: '/search?keyword=h5&num=1',
href: '/search?keyword=h5&num=1'
} */
// 获取url中的路径
console.log(res.pathname); // /search
// 获取url中的查询字符串
console.log(res.query.keyword); // h5
response.end("url");
});
// 3.监听端口,启动服务
server.listen(9000, () => {
console.log("服务在9000端口启动");
}); 2.方法二:通过实例化一个 url 对象
// 导入http模块
const http = require("http");
// 创建服务对象
const server = http.createServer((request, response) => {
// 实例化一个 url 对象
let url = new URL(request.url, "http://127.0.0.1");
console.log(url);
/* URL {
href: 'http://127.0.0.1/search?keyword=h5&num=1',
origin: 'http://127.0.0.1',
protocol: 'http:',
host: '127.0.0.1',
hostname: '127.0.0.1',
port: '',
pathname: '/search',
search: '?keyword=h5&num=1',
searchParams: URLSearchParams { 'keyword' => 'h5', 'num' => '1' },
hash: ''
} */
// 获取url的路径
console.log(url.pathname); // /search
// 获取url的查询字符串
console.log(url.searchParams.get('keyword')); // h5
response.end("url");
});
// 3.监听端口,启动服务
server.listen(9000, () => {
console.log("服务在9000端口启动");
});10.3练习
按照以下要求搭建 HTTP 服务
| 请求类型(方法) | 请求地址 | 响应体结果 |
|---|---|---|
| get | /login | 登录页面 |
| get | /reg | 注册页面 |
// 1.导入http模块
const http = require("http");
const { url } = require("inspector");
// 2.创建http服务
const server = http.createServer((request, response) => {
// 获取请求的方法
let { method } = request; // 对象解构赋值
// 获取请求的 url 路径 创建一个新的url 再对其进行解构
let { pathname } = new URL(request.url, "http://127.0.0.1");
console.log(method, pathname);
// 设置响应头 避免乱码
response.setHeader("Content-Type", "text/html;charset=UTF-8");
// 判断
if (method === "GET") {
if (pathname === "/login" || pathname === "/") {
response.end("登录页面"); // 每次请求只能有一个end()方法
} else if (pathname === "/reg") {
response.end("注册页面");
}else{ // 处理其它请求
response.end('404 Not Found')
}
}
});
// 监听端口,启动服务
server.listen(9000, () => {
console.log("Server is running at 8000");
});十一、设置 HTTP 响应报文
| 作用 | 语法 |
|---|---|
| 设置响应状态码 | response.statusCode |
| 设置响应状态描述 | response.statusMessage ( 用的非常少 ) |
| 设置响应头信息 | response.setHeader('头名', '头值') |
| 设置响应体 | response.write('xx') response.end('xxx') |
// 1.设置响应状态码(响应行)
/* response.statusCode = 203;
response.statusCode = 404; */
// 2.响应状态的描述(响应行)
// response.statusMessage = 'Not Found';
// 3.响应头
// response.setHeader("content-type", "text/html;charset=utf-8");
// response.setHeader('Server','Node.js')
response.setHeader("myHeader", "test test test"); // 自定义响应头
// 4.响应体
response.write("love");
response.write("u");
response.end(); // end 结束响应,必须有且之只能有一个
// response.end('love u') //效果与上面相同11.1练习
搭建 HTTP 服务,响应一个 4 行 3 列的表格,并且要求表格有 隔行换色效果 ,且 点击 单元格能 高亮显示
// 导入http模块
const http = require("http");
// 创建http服务对象
const server = http.createServer((request, response) => {
response.end(`<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
table,
td {
border: 1px solid black;
border-collapse: collapse;
}
table tr:nth-child(odd) {
background-color: #aef;
}
table tr:nth-child(even) {
background-color: #fcb;
}
td {
width: 180px;
height: 50px;
}
</style>
</head>
<body>
<table>
<tr>
<td></td>
<td></td>
<td></td>
</tr>
<tr>
<td></td>
<td></td>
<td></td>
</tr>
<tr>
<td></td>
<td></td>
<td></td>
</tr>
<tr>
<td></td>
<td></td>
<td></td>
</tr>
</table>
</body>
<script>
// 获取所有的td
let tds = document.querySelectorAll("td");
tds.forEach((td) => {
td.onclick = function () {
this.style.background = "red";
};
});
</script>
</html>
`);
});
// 监听端口 并启动服务
server.listen(9000, () => {
console.log("服务启动成功");
});11.2练习优化
// 导入http模块
const http = require("http");
// 导入fs 模块 将table.html中的内容 读出来写在response中
const fs = require("fs");
// 读取table.html中的buffer内容并存入到一个变量中
let html = fs.readFileSync(__dirname + "/10 table.html");
// __dirname:当前文件的目录的绝对路径 使用绝对路径避免相对路径的bug
// 创建http服务对象
const server = http.createServer((request, response) => {
response.end(html); // end()方法可以接收字符串或buffer对象
});
// 监听端口 并启动服务
server.listen(9000, () => {
console.log("服务启动成功");
});十二、网页资源的基本加载过程
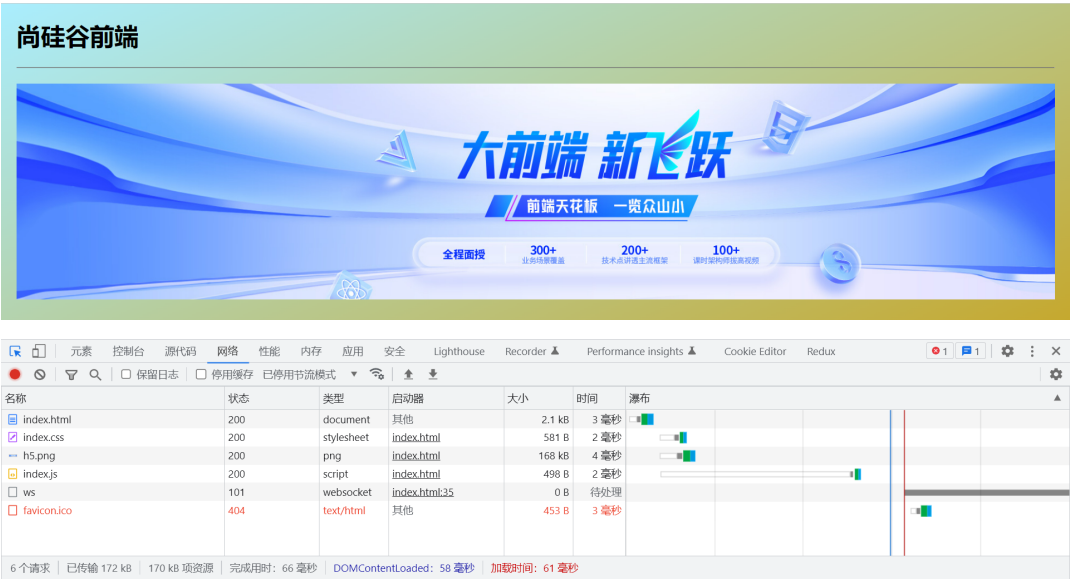
网页资源的加载都是循序渐进的,首先获取 HTML 的内容, 然后解析 HTML 在发送其他资源的请求,如 CSS,Javascript,图片等。 理解了这个内容对于后续的学习与成长有非常大的帮助
根据不同请求的不同路径返回不同的数据

// 获取请求url 的路径
let { pathname } = new URL(request.url, "http://127.0.0.1:80");
// 根据不同请求的不同url 返回不同的数据
if (pathname == "/") {
let html = fs.readFileSync(__dirname + "/11 table.html");
response.end(html); // end()方法可以接收字符串或buffer对象
} else if (pathname == "/index.css") {
let css = fs.readFileSync(__dirname + "/index.css");
response.end(css);
} else if (pathname == "/index.js") {
let js = fs.readFileSync(__dirname + "/index.js");
response.end(js);
} else {
response.statusCode = 404;
response.end("<h1>404</h1>");
}十三、静态资源服务
静态资源是指 内容长时间不发生改变的资源 ,例如图片,视频,CSS 文件,JS文件,HTML文件,字体文 件等
动态资源是指 内容经常更新的资源 ,例如百度首页,网易首页,京东搜索列表页面等
13.1访问静态资源服务:
前端发不同的请求,请求静态资源的文件。后端根据其url中的pathname返回不同的数据,每次都要对其进行获取和判断
简化其操作,让其根据pathname 去自动访问并返回静态资源
/*
创建一个 HTTP 服务,端口为 9000,满足如下的需求:
GET /index.html 响应 page/index.html 的文件内容
GET /css/aap.css 响应 page/css/app.css 的文件内容
GET /images.login.ong 响应 page/images/login.png 的文件内容
*/
// 导入http模块
const http = require("http");
// 导入fs 模块 将table.html中的内容 读出来写在response中
const fs = require("fs");
// 创建http服务对象
const server = http.createServer((request, response) => {
// 前端发请求,后端获取url路径 拼接为静态资源路 再读取其文件内容返回给前端
// 获取请求url 的路径
let { pathname } = new URL(request.url, "http://127.0.0.1:80");
// 拼接文件路径 filePath: 为静态资源路径
let filePath = __dirname + "/page" + pathname;
// 读取文件
fs.readFile(filePath, (err, data) => {
if (err) {
// 读取错误
response.statusCode = 500; // 错误响应
response.end("文件读取失败");
return; // 结束回调函数的运行
}
// 响应文件内容
response.end(data);
});
});
// 监听端口 并启动服务
server.listen(9000, () => {
console.log("服务启动成功");
});13.2 网站根目录或静态资源目录
HTTP 服务在哪个文件夹中寻找静态资源,那个文件夹就是 静态资源目录 ,也称之为 网站根目录
思考:vscode 中使用 live-server 访问 HTML 时, 它启动的服务中网站根目录是谁?
当前打开的文件夹作为网站根目录。
13.3网页中的 URL
网页中的 URL 主要分为两大类:相对路径与绝对路径
13.3.1绝对路径
绝对路径可靠性强,而且相对容易理解,在项目中运用较多
当前网页 url 为 http://atguigu.com/aa/bb/c.html
| 形式 | 特点 | 最终URL |
|---|---|---|
| http://atguigu.com/web | 直接向目标资源发送请求,容易理解。网站的外链会用到此形式 | http://atguigu.com/web |
| //atguigu.com/web | 与页面 URL 的协议拼接形成完整 URL 再发送请求。大型网站用的比较多 | http://atguigu.com/web |
| /web | 与页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求。中小型网站 | http://atguigu.com/web |
<!-- 会与页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求 -->
<a href="/search">搜索</a>
<!-- http://127.0.0.1:5500/search -->/ 绝对路径 ./ 相对路径
13.3.2相对路径
相对路径在发送请求时,需要与当前页面 URL 路径进行 计算 ,得到完整 URL 后,再发送请求,学习阶 段用的较多
例如当前网页 url 为 http://www.atguigu.com/course/h5.html
| 形式 | 最终的 URL |
|---|---|
| ./css/app.css | http://www.atguigu.com/course/css/app.css |
| js/app.js | http://www.atguigu.com/course/js/app.js |
| ../img/logo.png | http://www.atguigu.com/img/logo.png |
| ../../mp4/show.mp4 | http://www.atguigu.com/mp4/show.mp4 |
12.3.3 网页中使用 URL 的场景小结
包括但不限于如下场景:
- a 标签 href
- link 标签 href
- script 标签 src
- img 标签 src
- video audio 标签 src
- form 中的 action
- AJAX 请求中的 URL
在项目开发时设置路径时最好采用绝对路径的写法
<link rel="stylesheet" href="/css/app.css">13.4设置资源类型(mime类型)
媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、 文件或字节流的性质和格式。
mime 类型结构: [type]/[subType]
例如: text/html text/css image/jpeg image/png application/jsonHTTP 服务可以设置响应头 Content-Type 来表明响应体的 MIME 类型,浏览器会根据该类型决定如何处理 资源
下面是常见文件对应的 mime 类型
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'对于未知的资源类型,可以选择 application/octet-stream 类型,浏览器在遇到该类型的响应 时,会对响应体内容进行独立存储,也就是我们常见的 下载 效果
示例:
const path = require("path");
let mimes = {
html: "text/html",
css: "text/css",
js: "text/javascript",
png: "image/png",
jpg: "image/jpeg",
gif: "image/gif",
mp4: "video/mp4",
mp3: "audio/mpeg",
json: "application/json",
};
// 设置mime类型
// 1.获取文件后缀名
let ext = path.extname(filePath).slice(1);
console.log(ext);
// 2.获取对应的类型,并判断是否匹配
let type = mimes[ext] == null ? "application/octet-stream" : mimes[ext];
// 3.设置响应头
response.setHeader("content-type",type);上面代码设置与不设置 不影响效果,浏览器自带有mime嗅探功能,会根据返回的内容自动设置响应头。
13.5解决乱码问题
当返回内容有中文且出现乱码时,需要在响应头的mime类型后加上 ;charset=utf-8
// 设置响应头 返回的是文本类型,并设置字符集编码为utf-8
response.setHeader("content-type", "text/plain;charset=utf-8");
response.end("文件读取失败");
response.setHeader("content-type", `${type};charset=utf-8`);text/plain 表示内容的 MIME 类型是纯文本,浏览器或其他客户端接收到这样的响应时,会以普通文本的形式展示数据,而不是尝试解析为 HTML、JSON 等其他格式。
设字符集方式:
- 在html文件中设置
<meta charset="UTF-8">- 通过响应头设置
response.setHeader("content-type", `${type};charset=utf-8`);优先级:通过响应头设置 > 在html文件中设置
外部资源可以不设置响应头,当被引入html文件中时,会根据html文件的字符集设置自己的字符集。
13.6 完善错误处理
根据不同的错误返回不同的错误编号和错误提示
对读取文件出现的错误进行处理:
// 读取文件
fs.readFile(filePath, (err, data) => {
// 判断错误的代号
if (err) {
response.setHeader("content-type", "text/html;charset=utf-8");
switch (err.code) {
case "ENOENT": // 找不到资源
response.statusCode = 404;
response.end("<h1>404 Not Found</h1>");
case 'EPERM': // 权限不足
response.statusCode = 403;
response.end('<h1>403 Forbidden</h1>');
default : // 其它错误
response.statusCode = 500;
response.end('<h1>Internal Server Error</h1>')
}
return; // 结束回调函数的运行
}对请求方法错误的处理:
if(request.method !== "GET"){
response.statusCode = 405;
response.end('<h1>405 Method Not Allowed</h1>')
return;
}十四、GET和POST请求的区别
14.1GET 和 POST 请求场景
GET 请求的情况:
- 在地址栏直接输入 url 访问
- 点击 a 链接
- link 标签引入 css
- script 标签引入 js
- video 与 audio 引入多媒体
- img 标签引入图片
- form 标签中的 method 为 get (不区分大小写)
- ajax 中的 get 请求
POST 请求的情况:
- form 标签中的 method 为 post(不区分大小写)
- AJAX 的 post 请求
14.2GET和POST请求的区别
GET 和 POST 是 HTTP 协议请求的两种方式,主要有如下几个区别
- 作用:GET 主要用来获取数据,POST 主要用来提交数据
- 参数位置:GET 带参数请求是将参数缀到 URL 之后,在地址栏中输入 url 访问网站就是 GET 请求, POST 带参数请求是将参数放到请求体中
- 安全性:POST 请求相对 GET 安全一些,因为在浏览器中参数会暴露在地址栏
- 数据限制:GET 请求大小有限制,一般为 2K,而 POST 请求则没有大小限制(获取一些大文件时可以使用post)
5.Node.js 模块化
一、介绍
1.1 什么是模块化与模块 ?
将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为 模块化 其中拆分出的 每个文件就是一个模块 ,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他 模块使用
1.2 什么是模块化项目 ?
编码时是按照模块一个一个编码的, 整个项目就是一个模块化的项目
1.3 模块化好处
下面是模块化的一些好处:
- 防止命名冲突
- 高复用性
- 高维护性
二、模块暴露数据
2.1 模块初体验
可以通过下面的操作步骤,快速体验模块化
- 创建 me.js
// 声明一个函数
function tiemo(){
console.log('贴膜....');
}
// 暴露数据
module.exports = tiemo;- 创建 index.js
// 导入模块
const tiemo = require("./me.js");
// 测试
tiemo();2.2 暴露数据
模块暴露数据的方式有两种:
module.exports = value
js// 暴露数据 // 暴露单个变量 module.exports = tiemo; //暴露一个对象 module.exports = { tiemo, niejiao, }; // 导入模块 const me = require("./me.js"); console.log(me); // { tiemo: [Function: tiemo], niejiao: [Function: niejiao] } me.tiemo(); me.niejiao();exports.name = value
// exports 暴露数据
exports.niejiao = niejiao;
exports.tiemo = tiemo;
// 导入模块
const me = require("./me.js"); // 接收到的也为一个对象
console.log(me); // 将全部暴露的模块组成一个对象
// { tiemo: [Function: tiemo], niejiao: [Function: niejiao] }
me.tiemo();
me.niejiao();使用时有几点注意:
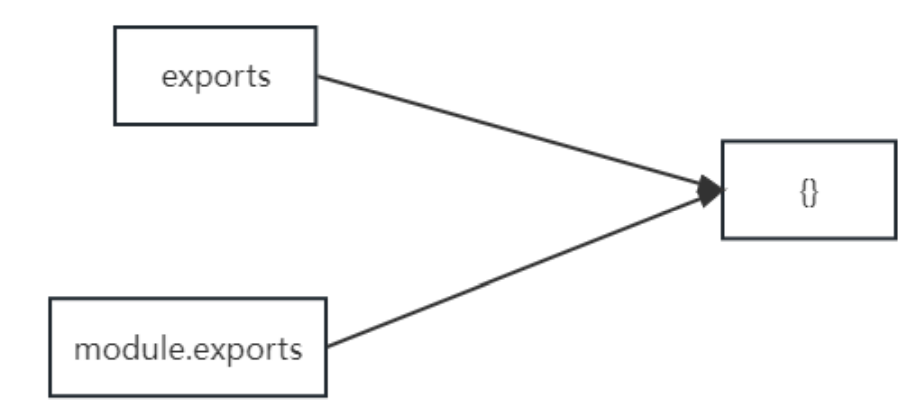
- module.exports 可以暴露 任意 数据
- 不能使用 exports = value 的形式暴露数据,模块内部 module 与 exports 的隐式关系 exports = module.exports = {} ,require 返回的是目标模块中 module.exports 的值
三、导入(引入)模块
在模块中使用 require 传入文件路径即可引入文件
const test = require('./me.js');
// 暴露的一般为一个对象,使用test接收暴露的对象require 使用的一些注意事项:
对于自己创建的模块,导入时路径建议写 相对路径 ,且不能省略 ./ 和 ../
js 和 json 文件导入时可以不用写后缀,c/c++编写的 node 扩展文件也可以不写后缀,但是一 般用不到
如果导入其他类型的文件,会以 js 文件进行处理
如果导入的路径是个文件夹,则会 首先 检测该文件夹下 package.json 文件中 main 属性对应 的文件, 如果存在则导入,反之如果文件不存在会报错。
如果 main 属性不存在,或者 package.json 不存在,则会尝试导入文件夹下的 index.js 和 index.json , 如果还是没找到,就会报错
导入 node.js 内置模块时,直接 require 模块的名字即可,无需加 ./ 和 ../
四、导入模块的基本流程
require 导入 自定义模块 的基本流程
- 将相对路径转为绝对路径,定位目标文件
- 缓存检测
- 读取目标文件代码
- 包裹为一个函数并执行(自执行函数)。通过 arguments.callee.toString() 查看自执行函数
- 缓存模块的值
- 返回 module.exports 的值
五、CommonJS 规范
module.exports 、 exports 以及 require 这些都是 CommonJS 模块化规范中的内容。
而 Node.js 是实现了 CommonJS 模块化规范,二者关系有点像 JavaScript 与 ECMAScript
6.包管理工具
一、概念介绍
1.1 包是什么
『包』英文单词是 package ,代表了一组特定功能的源码集合
1.2 包管理工具
管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作
借助包管理工具,可以快速开发项目,提升开发效率
包管理工具是一个通用的概念,很多编程语言都有包管理工具,所以 掌握好包管理工具非常重要
1.3 常用的包管理工具
下面列举了前端常用的包管理工具
- npm
- yarn
- cnpm
- pnpm
- bun
二、npm
npm 全称 Node Package Manager ,翻译为中文意思是『Node 的包管理工具』
npm 是 node.js 官方内置的包管理工具,是 必须要掌握住的工具
2.1 npm 的安装
node.js 在安装时会 自动安装 npm ,所以如果你已经安装了 node.js,可以直接使用 npm
可以通过 npm -v 查看版本号测试,如果显示版本号说明安装成功,反之安装失败

2.2 npm 基本使用
2.2.1 初始化
创建一个空目录,然后以此目录作为工作目录 启动命令行工具 ,执行 npm init
或执行npm init y 快速生成,前提是当前文件夹名为英文。
npm init 命令的作用是将文件夹初始化为一个『包』, 交互式创建 package.json 文件
package.json 是包的配置文件,每个包都必须要有 package.json
package.json 内容示例:
{
"name": "test", // 包的名字
"version": "1.0.0", // 包的版本
"description": "学习npm", //包的描述
"main": "index.js", // 包的入口文件
"scripts": { // 脚本设置
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "", // 作者
"license": "ISC" // 开源证书
}注意:
- package name ( 包名 ) 不能使用中文、大写,默认值是 文件夹的名称 ,所以文件夹名称也不 能使用中文和大写
- version ( 版本号 )要求 x.x.x 的形式定义, x 必须是数字,默认值是 1.0.0
- ISC 证书与 MIT 证书功能上是相同的,关于开源证书扩展阅读http://www.ruanyifeng.com/bl og/2011/05/how_to_choose_free_software_licenses.html
- package.json 可以手动创建与修改
- 使用 npm init -y 或者 npm init --yes 极速创建 package.json
- 安装依赖包时,会自动自下往上搜索,在项目的子文件夹中安装依赖,若没有package.json文件会自动向父文件中搜索,将依赖包安装至父文件中。
2.2.2 搜索包
搜索包的方式有两种
- 命令行 『npm s/search 关键字』
- 网站搜索 网址是 https://www.npmjs.com/
2.2.3 下载安装包
我们可以通过 npm install 和 npm i 命令安装包
格式:
npm install <包名>
npm i <包名>示例:
npm install uniq
npm i uniq运行之后文件夹下会增加两个资源
- node_modules 文件夹 存放下载的包
- package-lock.json 包的锁文件 ,用来锁定包的版本
安装 uniq 之后, uniq 就是当前这个包的一个 依赖包 ,有时会简称为 依赖
比如我们创建一个包名字为 A,A 中安装了包名字是 B,我们就说 B 是 A 的一个依赖包 ,也会说 A 依赖 B
2.2.4使用包
// 1.导入 uniq 包,和导入NodeJS内部模块用法相同
const uniq = require("uniq"); // 数组去重
// 2.使用函数
let arr = [1, 2, 3, 2, 2, 21, 341, 31, 3];
let result = uniq(arr);
// result = require('uniq')(arr); 只使用一次的简便写法
console.log(result);2.2.5 require 导入 npm 包基本流程
在当前文件夹下 node_modules 中寻找同名的文件夹
在文件夹中寻找package.json中的 ‘main’ 对应的js文件

在‘uniq.js'中查看暴露的内容

在上级目录中下的 node_modules 中寻找同名的文件夹,直至找到磁盘根目录
// const uniq = require("uniq"); 推荐写法
// const uniq = require('./node_modules/uniq') 与上面写法等同
const uniq = require('./node_modules/uniq/uniq.js') 与上面写法等同2.3 生产环境与开发环境
开发环境(development)是程序员 专门用来写代码 的环境,一般是指程序员的电脑,开发环境的项目一般 只能程序员自 己访问
生产环境(production)是项目 代码正式运行 的环境,一般是指正式的服务器电脑,生产环境的项目一般 每个客户都可 以访问
2.4 生产依赖与开发依赖
我们可以在安装时设置选项来区分 依赖的类型 ,目前分为两类:
| 类型 | 命令 | 补充 |
|---|---|---|
| 生产依赖 | npm i -S uniq npm i --save uniq | -S 等效于 --save, -S 是默认选项 包信息保存在 package.json 中 dependencies 属性 |
| 开发依赖 | npm i -D less npm i --save-dev less | -D 等效于 --save-dev 包信息保存在 package.json 中 devDependencies 属性 |
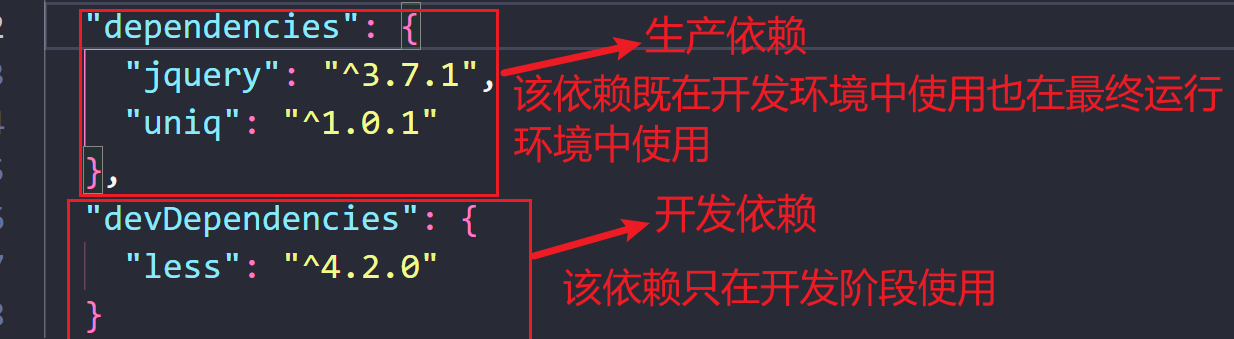
比如说做蛋炒饭需要 大米 , 油 , 葱 , 鸡蛋 , 锅 , 煤气 , 铲子 等
其中 锅 , 煤气 , 铲子 属于开发依赖,只在制作阶段使用
而 大米 , 油 , 葱 , 鸡蛋 属于生产依赖,在制作与最终食用都会用到
所以 开发依赖 是只在开发阶段使用的依赖包,而 生产依赖 是开发阶段和最终上线运行阶段都用到 的依赖包
生产依赖和开发依赖的包都在node_modules中
2.5 全局安装
我们可以执行安装选项 -g 进行全局安装
npm i -g nodemon全局安装完成之后就可以在命令行的任何位置运行 nodemon 命令
该命令的作用是 自动重启 node 应用程序
说明:
- 全局安装的命令不受工作目录位置影响
- 可以通过 npm root -g 可以查看全局安装包的位置
- 不是所有的包都适合全局安装 , 只有全局类的工具才适合,可以通过 查看包的官方文档来确定 安装方式 ,这里先不必太纠结
2.5.1 修改 windows 执行策略
windows 默认不允许 npm 全局命令执行脚本文件,所以需要修改执行策略

- 以 管理员身份 打开 powershell 命令行
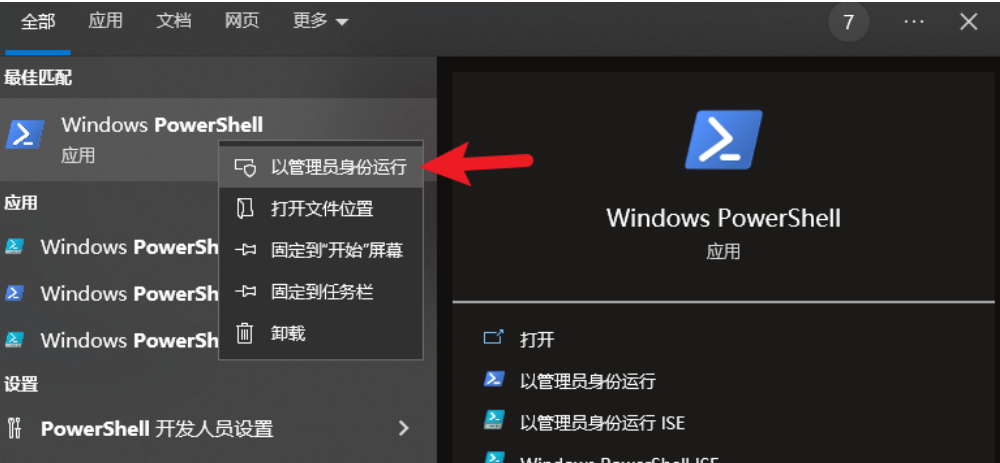
- 键入命令
set-ExecutionPolicy remoteSigned
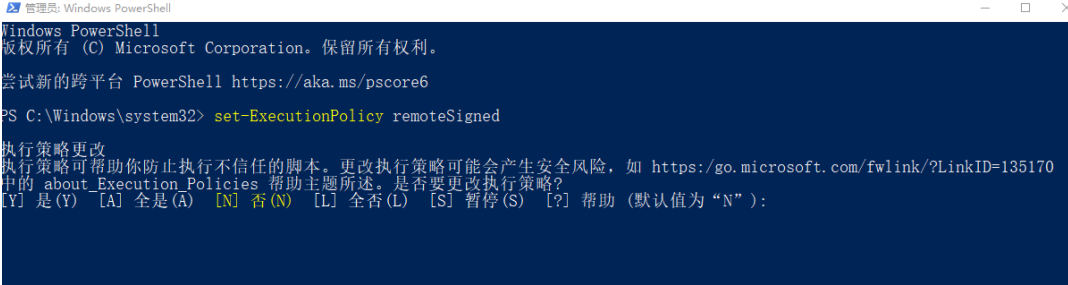
- 键入 A 然后敲回车 👌
- 如果不生效,可以尝试重启 vscode
2.5.2 修改VSCode终端为cmd
当出现上面错误时,可以不修改windows 执行策略,直接将VSCode的终端由PowerShell改为cmd即可。
PowerShell提供了比CMD更强大和灵活的命令行体验,尤其适合于需要进行复杂自动化和配置管理的高级用户。
2.5.3 环境变量 Path
Path 是操作系统的一个环境变量,可以设置一些文件夹的路径,在当前工作目录下找不到可执行文件 时,就会在环境变量 Path 的目录中挨个的查找,如果找到则执行,如果没有找到就会报错
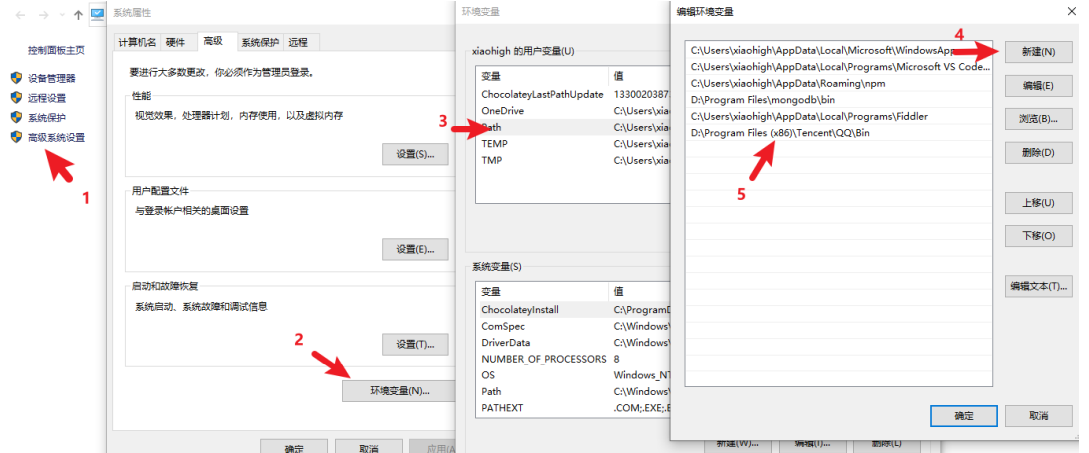
当你希望在命令行的任意位置都可以执行程序的时候,就可以通过配置环境变量来实现
将QQ的bin目录配置到 用户的环境变量Path中
就可以通过在任意的cmd窗口中输入QQ 打开QQ了
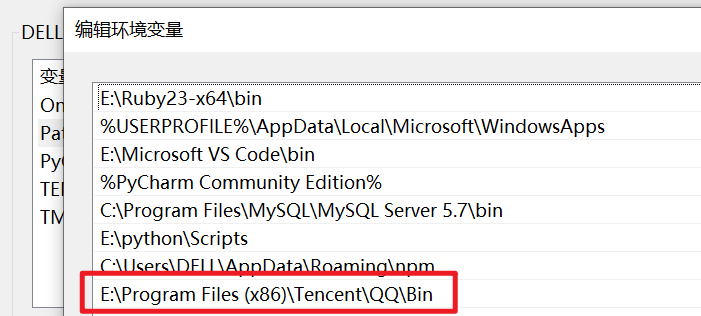
补充说明:
- 如果希望某个程序在任何工作目录下都能正常运行,就应该将该程序的所在(bin)目录配置到 用户 的环境变量 Path 中
- windows 下查找命令的所在位置
- cmd 命令行 中执行 where nodemon
- powershell命令行 执行 get-command nodemon
2.6 安装包依赖
使用npm i 安装在 package.json 和 packagelock.json 中所指定的全部依赖包
在项目协作中有一个常用的命令就是 npm i ,通过该命令可以依据 package.json 和 packagelock.json 的依赖声明 安装项目依赖
npm i
npm installnode_modules 文件夹大多数情况都不会存入(svn/git)版本库
node_modules 中的文件太多,占用内存太大,不利于上传和下载(配置 .gitignore)
克隆下来的仓库是不带 node_modules的 所以需要使用npm i 把所有的依赖全部安装
2.7 安装指定版本的包
项目中可能会遇到版本不匹配的情况,有时就需要安装指定版本的包,可以使用下面的命令的
## 格式
npm i <包名@版本号>
## 示例
npm i jquery@1.11.22.8 删除依赖/包
项目中可能需要删除某些不需要的包,可以使用下面的命令
## 局部删除
npm remove uniq
npm r uniq
## 全局删除
npm remove -g nodemon2.9 配置命令别名
通过配置命令别名可以更简单的执行命令
配置 package.json 中的 scripts 属性
{
.
.
.
"scripts": {
"server": "node server.js",
"start": "node index.js",
},
.
.
}配置完成之后,可以使用别名执行命令
npm run server
npm run start不过 start 别名比较特别,使用时可以省略 run
npm start补充说明:
- npm start 是项目中常用的一个命令,一般用来启动项目
- npm run 有自动向上级目录查找的特性,跟 require 函数也一样
- 对于陌生项目的启动,我们可以通过查看 scripts 属性来参考项目的一些操作
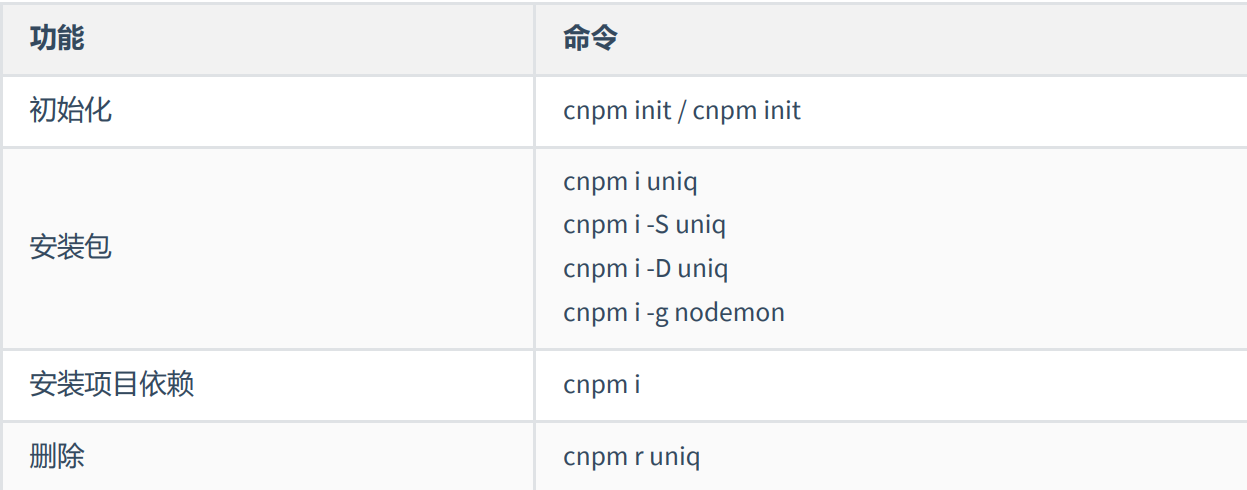
三、cnpm
3.1 介绍
cnpm 是一个淘宝构建的 npmjs.com 的完整镜像,也称为『淘宝镜像』,网址https://npmmirror.com/
cnpm 服务部署在国内 阿里云服务器上 , 可以提高包的下载速度
官方也提供了一个全局工具包 cnpm ,操作命令与 npm 大体相同
淘宝镜像只可以下载包,不能上传包,想要上传包需要使用官方的npm镜像
3.2 安装
我们可以通过 npm 来安装 cnpm 工具
npm install -g cnpm --registry=https://registry.npmmirror.com3.3 操作命令
3.4 npm 配置淘宝镜像
用 npm 也可以使用淘宝镜像,配置的方式有两种
- 直接配置
- 工具配置
3.4.1 直接配置
执行如下命令即可完成配置
npm config set registry https://registry.npmmirror.com/3.4.2 工具配置
使用 nrm 配置 npm 的镜像地址 npm registry manager
安装 nrm
npm i -g nrm修改镜像
nrm use taobao检查是否配置成功(选做)
npm config list检查 registry 地址是否为 https://registry.npmmirror.com/ , 如果 是 则表明成功
切换其它镜像
jsnrm ls // 查看支持的镜像地址 nrm use npm // 切换到官方地址 或其它地址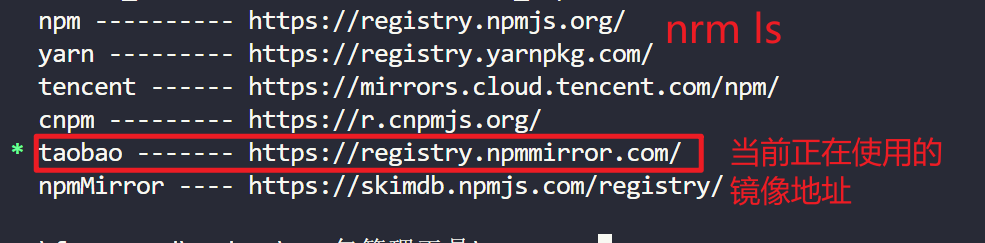
补充说明:
- 建议使用第二种方式 进行镜像配置,因为后续修改起来会比较方便
- 虽然 cnpm 可以提高速度,但是 npm 也可以通过淘宝镜像进行加速,所以 npm 的使用率还 是高于 cnpm
四、yarn
4.1 yarn 介绍
yarn 是由 Facebook 在 2016 年推出的新的 Javascript 包管理工具,官方网址:https://yarnpkg.com/
4.2 yarn 特点
yarn 官方宣称的一些特点
- 速度超快:yarn 缓存了每个下载过的包,所以再次使用时无需重复下载。 同时利用并行下载以最大 化资源利用率,因此安装速度更快
- 超级安全:在执行代码之前,yarn 会通过算法校验每个安装包的完整性
- 超级可靠:使用详细、简洁的锁文件格式和明确的安装算法,yarn 能够保证在不同系统上无差异的 工作
4.3 yarn 安装
我们可以使用 npm 安装 yarn
npm i -g yarn4.4 yarn 常用命令

注意:
这里有个小问题就是 全局安装的包不可用 ,yarn 全局安装包的位置可以通过 yarn global bin 来查看,
那你有没有办法使 yarn 全局安装的包能够正常运行?
为系统配置 yarn 的环境变量 将 yarn global bin 的存放目录配置系统的环境变量中
4.5 yarn 配置淘宝镜像
可以通过如下命令配置淘宝镜像
yarn config set registry https://registry.npmmirror.com/可以通过 yarn config list 查看 yarn 的配置项
4.6 npm 和 yarn 选择
大家可以根据不同的场景进行选择
- 个人项目 如果是个人项目, 哪个工具都可以 ,可以根据自己的喜好来选择
- 公司项目 如果是公司要根据项目代码来选择,可以 通过锁文件判断 项目的包管理工具
- npm 的锁文件为 package-lock.json
- yarn 的锁文件为 yarn.lock
包管理工具 不要混着用,切记,切记,切记
五、管理发布包
5.1 创建与发布
我们可以将自己开发的工具包发布到 npm 服务上,方便自己和其他开发者使用,操作步骤如下:
- 创建文件夹,并创建文件 index.js(与package.json中的main属性值对应), 在文件中声明函数,使用 module.exports 暴露
- npm 初始化工具包,package.json 填写包的信息 (包的名字是唯一的)
- 注册账号 https://www.npmjs.com/signup
- 激活账号 ( 一定要激活账号 )
- 修改为官方的官方镜像 (命令行中运行 nrm use npm )
- 命令行下 npm login 填写相关用户信息
- 命令行下 npm publish 提交包 👌
5.2 更新包
后续可以对自己发布的包进行更新,操作步骤如下
更新包中的代码
测试代码是否可用
修改 package.json 中的版本号
发布更新
npm publish
5.3 删除包
执行如下命令删除包
npm unpublish --force删除包需要满足一定的条件,https://docs.npmjs.com/policies/unpublish
你是包的作者
发布小于 24 小时
大于 24 小时后,没有其他包依赖,并且每周小于 300 下载量,并且只有一个维护者
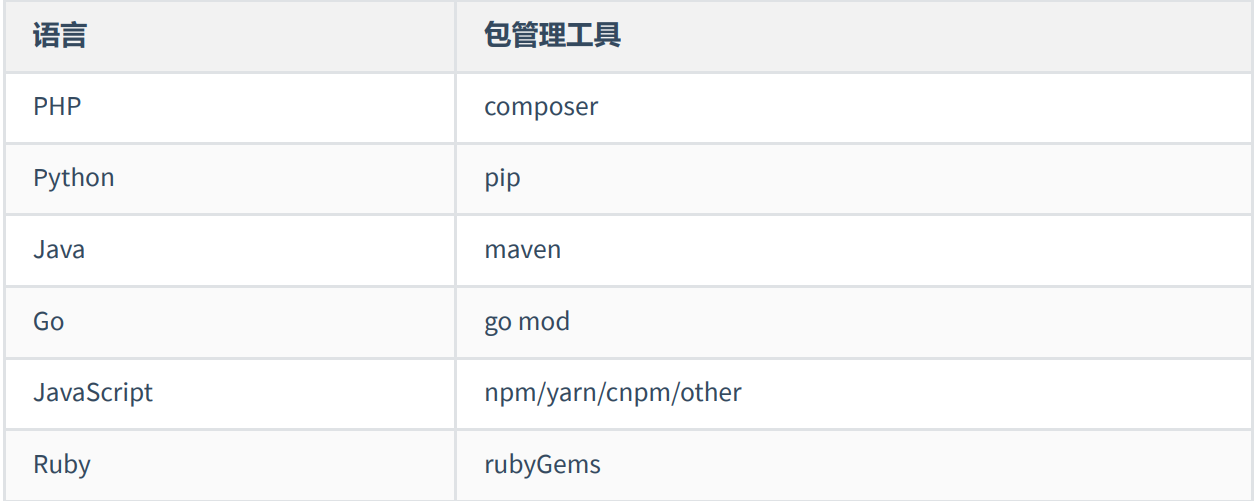
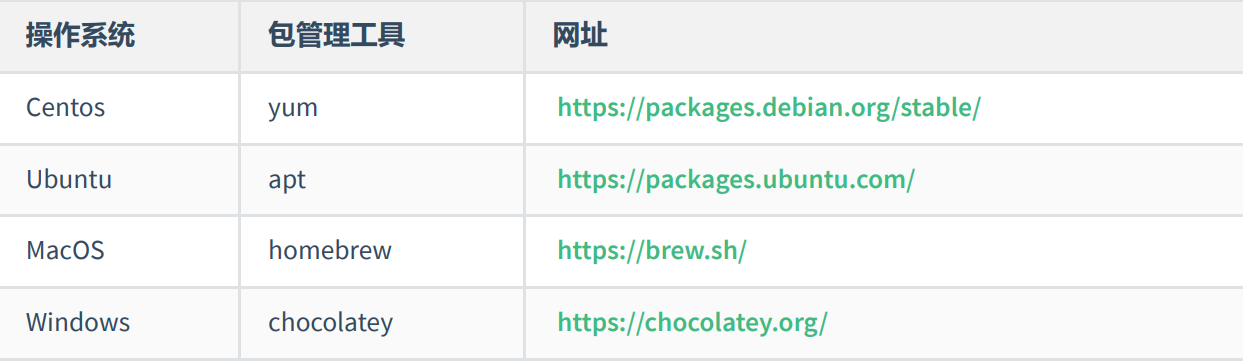
六、扩展内容
在很多语言中都有包管理工具,比如:
除了编程语言领域有包管理工具之外,操作系统层面也存在包管理工具,不过这个包指的是『 软件包 』
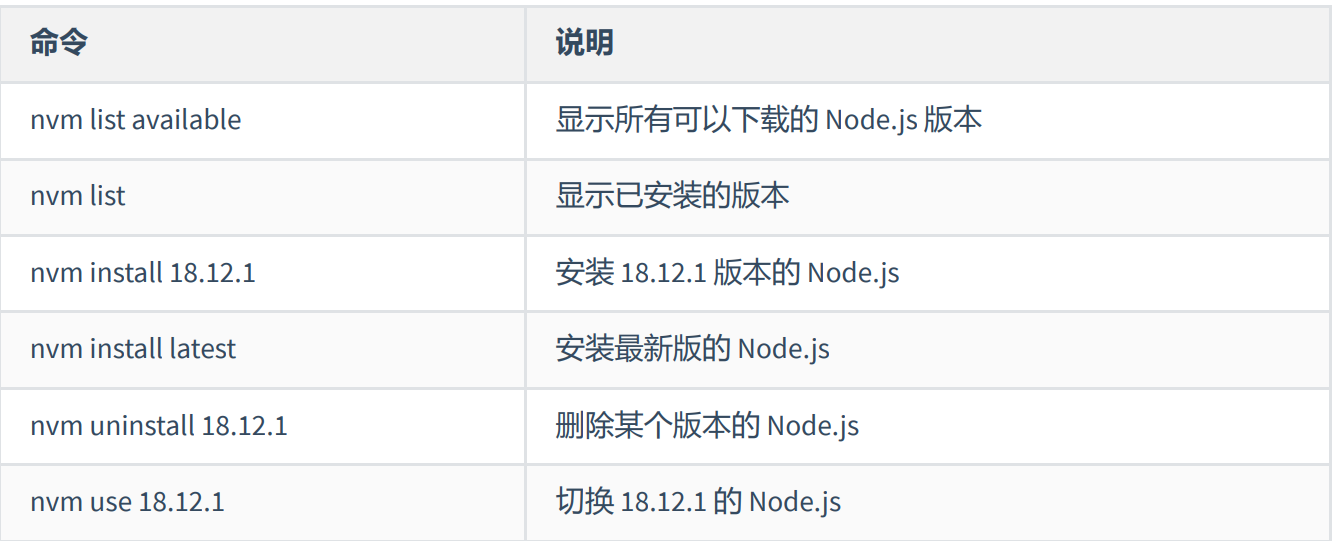
七、nvm
7.1 介绍
nvm 全称 Node Version Manager 顾名思义它是用来管理 node 版本的工具,方便切换不同版本的 Node.js
可以使用nvm进行nodejs版本的切换,也可以卸载掉当前本nodejs版重新安装指定的版本
7.2 使用
nvm 的使用非常的简单,跟 npm 的使用方法类似
7.3 下载安装
首先先下载 nvm,下载地址 https://github.com/coreybutler/nvm-windows/releases,
选择 nvm-setup.exe 下载即可
7.4 常用命令
7.express框架
一、express 介绍
express 是一个基于 Node.js 平台的极简、灵活的 WEB 应用开发框架,官方网址:https://www.expressjs.com.cn/
简单来说,express 是一个封装好的工具包,封装了很多功能,便于我们开发 WEB 应用(HTTP 服务)
二、express 使用
2.1 express 下载
express 本身是一个 npm 包,所以可以通过 npm 安装
npm init
npm i express2.2 express 初体验
创建package.json文件,并安装express
npm init npm i expresss创建 JS 文件,键入如下代码
// 1.导入express
const express = require("express");
// 2.创建应用对象
const app = express();
// 3.创建路由
app.get("/home", (req, res) => {
res.send("首页");
});
// 4.监听端口,启动服务
app.listen(3000, () => {
console.log("服务启动成功,端口3000");
}); 3.命令行下执行该脚本
node/nodemon 文件名 4. 然后在浏览器就可以访问 http://127.0.0.1:3000/home 👌
三、express 路由
3.1 什么是路由
官方定义: 路由确定了应用程序如何响应客户端对特定端点的请求
3.2 路由的使用
一个路由的组成有 请求方法 , 路径 和 回调函数 组成
express 中提供了一系列方法,可以很方便的使用路由,使用格式如下:
app.<method>(path,callback)代码示例:
// 导入express
const express = require("express");
// 创建应用对象
const app = express();
// 创建路由
// get 请求且为根目录
app.get("/", (req, res) => {
res.send("index");
});
// post请求
app.post("/login", (req, res) => {
res.send("login");
});
// 匹配所有的请求方法 all:所有方法
app.all("/test", (req, res) => {
res.send("test");
});
// 404响应 *:匹配所有路径
app.all("*", (req, res) => {
res.send("404 Not Found");
});
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务已启动");
});3.3 获取请求参数
express 框架封装了一些 API 来方便获取请求报文中的数据,并且兼容原生 HTTP 模块的获取方式
| API | 描述 |
|---|---|
| req.method | 获取请求方法 |
| req.url | 获取请求url(path+query)路径+查询字符串 |
| req.path | 获取请求路径 |
| req.query | 获取查询字符串 |
| req.ip | 获取客户端ip |
| req.get("host") | 获取请求头中指定的内容 如:host、token |
| req.query.变量名 | 获取前端get请求发来的数据 |
| req.body.变量名 | 获取前端post请求发来的数据 |
| req.params.变量名 | 获取前端传递的path参数 需要通过 xx/:id/:name 的形式接收 |
// 导入express
const express = require("express");
// 创建应用对象
const app = express();
// 创建路由
app.get("/request", (req, res) => {
// 原生操作
console.log(req.method); //获取请求方法 GET
console.log(req.url); // 获取请求URL /request?a=100&b=300
// express
console.log(req.path); //获取请求路径 /request
console.log(req.query); // 获取查询字符串 { a: '100', b: '300' }
// 获取客户端IP
console.log(req.ip); // ::ffff:127.0.0.1
// 获取请求头
console.log(req.get("host")); //127.0.0.1:3000
res.send("hello");
});
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务已启动");
});3.4 获取路由参数
路由参数指的是 URL 路径中的参数(数据)
// 创建路由 id:占位符
app.get("/:id.html", (req, res) => {
// 获取路由参数
console.log(req.params.id);
res.send("商品页");
});
// 输入http://127.0.0.1:3000/133.html 返回1333.4 路由参数练习
需求:根据路由参数来响应歌手信息
路径结构如下:
/singer/1.html显示歌手的姓名和图片
{
"singers": [
{
"singer_name": "周杰伦",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.webp",
"other_name": "Jay Chou",
"singer_id": 4558,
"id": 1
},
{
"singer_name": "林俊杰",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000001BLpXF2DyJe2.webp",
"other_name": "JJ Lin",
"singer_id": 4286,
"id": 2
},
{
"singer_name": "G.E.M. 邓紫棋",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000001fNHEf1SFEFN.webp",
"other_name": "Gloria Tang",
"singer_id": 13948,
"id": 3
},
{
"singer_name": "薛之谦",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000002J4UUk29y8BY.webp",
"other_name": "",
"singer_id": 5062,
"id": 4
}
]
}四、express 响应设置
express 框架封装了一些 API 来方便给客户端响应数据,并且兼容原生 HTTP 模块的获取方式
app.get("/response", (req, res) => {
// 原生响应
res.statusCode = 200;
res.statusMessage = "love";
res.setHeader("xxx", "yyy");
res.write("hello");
res.end();
// express 的响应方法
res.status(500); // 设置状态码
res.set('aaa','bbb'); // 设置响应头
res.send("不会乱码 hello"); // 设置响应体 会自动设置字符编码不会导致乱码
res.status(200).set('aaa','bbb').send('连缀设置')
});其它的一些响应
app.get("/other", (req, res) => {
// 跳转响应 / 重定向
res.redirect("https://www.baidu.com/");
// 下载响应
res.download(__dirname + "/package.json"); // 绝对路径
// JSON响应 向客户端发送JSON数据
res.json({
name: "张三",
age: "18",
});
// 响应文件内容(html页面)
res.sendFile(__dirname + "/02_form.html"); //绝对路径
// 渲染(esj模板)
res.render("./02_form.ejs"); // 相对路径
});注意:
res.send()方法用于向客户端发送响应,并结束响应过程。有如下功能:
- 结束响应
- 自动设置Content-Type
- 不支持多次调用
如果需要分阶段响应或条件性的发送不同的内容,可以使用多个 res.write() 最后使用 res.end()结束响应
五、express 中间件
5.1 什么是中间件
中间件(Middleware)本质是一个回调函数
中间件函数 可以像路由回调一样访问 请求对象(request) , 响应对象(response)
5.2 中间件的作用
中间件的作用 就是 使用函数封装公共操作,简化代码
5.3 中间件的类型
- 全局中间件
- 路由中间件
- 错误处理中间件
5.3.1 定义全局中间件
每一个请求 到达服务端之后 都会先执行全局中间件函数
声明中间件函数:
let recordMiddleware = function(req,res,next){
//实现功能代码
//.....
//执行next函数(当如果希望执行完中间件函数之后,仍然继续执行路由中的回调函数,必须调用next)
next();
}应用中间件:
app.use(recordMiddleware);声明时可以直接将匿名函数传递给 use:
app.use((req, res, next) => {
console.log('定义第一个中间件');
next();
})5.3.2全局中间件实例
需求:
记录每个请求的 url 和 ip 地址,并存入到access.log中
// 导入express
const express = require("express");
const fs = require("fs"); // 追加内容使用
const path = require("path"); // 获取绝对路径使用
// 创建应用对象
const app = express();
// 声明中间件函数 可以为匿名函数,箭头函数....
function recordMiddleware(req, res, next) {
// req:请求报文对象,res:响应报文对象,next:执行下一个中间件
// 获取url 和 ip
let { url, ip } = req; // 对象解构
// 将信息保存在文件中 access.log
fs.appendFileSync( // 追加内容
path.resolve(__dirname, "./access.log"), //获取文件的绝对路径
`${url} ${ip}\r\n` // 追加内容 \r\n换行
);
// 执行后续的路由回调
next();
}
// 使用全局中间件函数,在任何路由执行前都会先执行全局中间件
app.use(recordMiddleware);
// 创建路由
app.get("/home", (req, res) => {
res.send("前端首页");
});
app.get("/admin", (req, res) => {
res.send("后台首页");
});
app.all("*", (req, res) => {
res.send("<h1>404 Not Found</h1>");
});
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务启动成功,端口3000");
});在浏览器地址栏输入http://127.0.0.1:3000/admin,http://127.0.0.1:3000/home
在access.log中会增加新的内容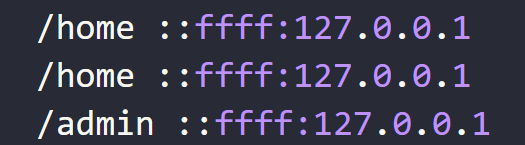
注意:当执行完中间件函数之后,仍然继续执行路由中的回调函数,必须调用next()
5.3.3 多个全局中间件
express 允许使用 app.use() 定义多个全局中间件
app.use(function (req, res, next) {
console.log('定义第一个中间件');
next();
})
app.use((req, res, next) => {
console.log('定义第二个中间件');
next();
})5.3.4 定义路由中间件
如果 只需要对某一些路由进行功能封装 ,则就需要路由中间件
调用格式如下:
app.get('/路径',`中间件函数`,(request,response)=>{
});
app.get('/路径',`中间件函数1`,`中间件函数2`,(request,response)=>{
});5.3.5路由中间件实例
需求:针对 /admin /setting 的请求,要求 URL 携带code=521 参数,如未携带提示(token鉴权)
// 导入express
const express = require("express");
// 创建应用对象
const app = express();
// 声明路由中间件
let checkCodeMiddleware = (req, res, next) => {
// 判断 URL 中是否 code 参数等于521
if (req.query.code === "521") {
next(); // 如果满足条件,就去调用后面的路由回调函数
} else {
res.send("请携带code=521参数"); // 结束响应就不再执行后面的路由回调
}
};
// 创建路由
app.get("/home", (req, res) => {
res.send("前端首页");
}); // 满足 /admin 后先执行路由中间件如果满足条件执行next() 最后执行路由回调函数
app.get("/admin", checkCodeMiddleware, (req, res) => { // 设置路由中间件
res.send("后台首页");
});
app.get("/setting", checkCodeMiddleware, (req, res) => { // 设置路由中间件
res.send("设置");
});
app.all("*", (req, res) => {
res.send("<h1>404 Not Found</h1>");
});
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务启动成功,端口3000");
});5.4 静态资源中间件
express 内置处理静态资源的中间件
静态资源:css、js、图片、html
静态资源目录/网站根目录:存放静态资源的文件夹
// 静态资源中间件设置
app.use(express.static(__dirname + "/public"));
//__dirname + "/public":静态资源文件夹目录的绝对路径注意事项:
- 静态资源目录中的 index.html 文件为默认打开的资源 (在地址栏输入项目根目录下默认打开)默认index.html为首页
- 如果静态资源与路由规则同时匹配,谁先匹配谁就响应
- 路由响应动态资源,静态资源中间件响应静态资源
5.4.1静态资源中间件练习
需求:局域网内可以访问 尚品汇 的网页
const express = require("express");
const app = express();
// 设置静态资源中间件
app.use(express.static(__dirname + "/尚品汇")); // 静态目录绝对路径
app.all("*", (req, res) => {
res.send("<h1>404 Not Found</h1>");
});
app.listen(3000, () => {
console.log("服务器已启动");
});查看局域网 ip 地址 并在其它设备打开网站:
打开cmd
输入:ipconfig
找到 IPv4 地址:192.168.1.9
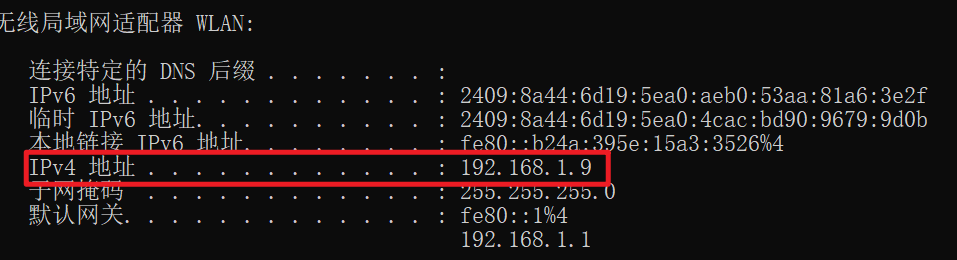
保证手机和电脑在同一局域网下
在手机上输入 ip 地址:192.168.1.9:3000 即可访问
5.5 获取请求体数据 body-parser
express 可以使用 body-parser 包处理请求体
在生成的express项目中会自带这部分功能
第一步:安装
npm i body-parser第二步:导入 body-parser 包
const bodyParser = require('body-parser');第三步:获取中间件函数
//处理 querystring 格式的请求体
let urlParser = bodyParser.urlencoded({extended:false}));
//处理 JSON 格式的请求体
let jsonParser = bodyParser.json()第四步:设置路由中间件,然后使用 request.body 来获取请求体数据
app.post('/login', urlParser, (request,response)=>{
//获取请求体数据
console.log(request.body);
//用户名
console.log(request.body.username);
//密码
console.log(request.body.userpass);
response.send('获取请求体数据');
});获取到的请求体数据:
[Object: null prototype] { username: 'admin', userpass: '123456' }六、防盗链
防盗链通常是指一种网络技术手段,用于防止他人未经授权使用或盗取自己服务器上的资源。
案例:
使静态资源目录下的文件只能在 127.0.0.1 主机下访问
// 导入express
const express = require("express");
// 创建应用对象
const app = express();
// 声明中间件 让静态资源只能在127.0.0.1访问
app.use((req, res, next) => {
// 检测请求头中的 referer 是否为 127.0.0.1
// 获取 referer
let referer = req.get("referer"); //req.get() 获取请求头中字段的数据
console.log(referer); //http://127.0.0.1:3000/
if (referer) { // 在第一次发请求访问 index.html 时无 referer
// 实例化
let url = new URL(referer);
// 获取 hostname
let hostname = url.hostname;
console.log(hostname);
// 判断
if (hostname !== "127.0.0.1") {
// 响应404
res.status(404).send("<h1>404 Not Found </h1>");
return;
}
}
next(); // 继续执行后续中间件
});
// 静态资源中间件设置
app.use(express.static(__dirname + "/public"));
//__dirname + "/public":静态资源文件夹目录
// 默认在根目录下打开 静态资源目录下的 index.html 文件
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务启动成功,端口3000");
});七、Router
7.1 什么是 Router
express 中的 Router 是一个完整的中间件和路由系统,可以看做是一个小型的 app 对象。
7.2 Router 作用
对路由进行模块化,更好的管理路由
7.3 Router 使用
在 routes 文件夹下创建 独立的JS文件(homeRouter.js)
//1. 导入 express
const express = require('express');
//2. 创建路由器对象
const router = express.Router();
//3. 在 router 对象身上添加路由
router.get('/', (req, res) => {
res.send('首页');
})
router.get('/cart', (req, res) => {
res.send('购物车');
});
//4. 暴露
module.exports = router;主文件(app.js)
const express = require('express');
const app = express();
//5.引入子路由文件
const homeRouter = require('./routes/homeRouter');
//6.设置和使用中间件
app.use(homeRouter); // http://127.0.0.1:3000/cart 访问
// 设置中间件时为设置路由规则
app.use('/home',honeRouter); // http://127.0.0.1:3000/home/cart 访问
// 启动服务
app.listen(3000,()=>{
console.log('3000 端口启动....');
})八、EJS 模板引擎
8.1 什么是模板引擎
模板引擎是分离 用户界面和业务数据 (html 和 javascript)的一种技术
随着前后端的分离,模板引擎使用量减少
在开发项目渲染界面时我们很多时候会用采用 js 拼接字符串的方式,会让整个代码很丑陋,还破坏原有的html结构,大量的html拼接会让代码难以阅读,而解决问题的方式就是使用模板。
8.2 什么是 EJS
EJS(Embedded JavaScript)嵌入式JavaScript,是一个高效的 Javascript 的模板引擎
官网: https://ejs.co/
使用 ejs 可以进行服务器端渲染 (见项目:supermarket)
res.render('./views/index.ejs')
// 响应请求渲染一个 ejs 页面8.3 EJS 初体验
下载安装EJS
npm i ejs --save// 导入 ejs
const ejs = require("ejs");
// 西游记
const xiyou = ["唐僧", "孙悟空", "猪八戒", "沙和尚"];
// 原生js
let str = "<ul>";
xiyou.forEach((item) => {
str += `<li>${item}</li>`;
});
// 闭合 ul
str += "</ul>";
console.log(str);
// EJS 实现
let str2 = ejs.render(
`
<ul>
<% for(let item of xiyou ){ %>
<li><%= item %></li>
<% } %>
</ul>
`,
{ xiyou }
);
console.log(str2);8.4 EJS 常用语法
执行JS代码
<% code %> // coede 为要执行的js代码输出转义的数据到模板上
<%= code %> // 将 code 的值输出到html中输出非转义的数据到模板上
<%- code %>在ejs中使用for循环:(将JavaScript代码写入到<%%>中)
<ul>
<% for(let item of xiyou ){ %>
<li><%= item %></li>
<% } %> // 闭合大括号
</ul>在ejs中获取变量的值:
<%= reslut.product[0].img%> // %和=之间不能有空格在 ejs 中使用 if 语句
<% if(isLogin) {%>
<span>欢迎回来</span>
<% }else{ %>
<button>登录</button> <button>注册</button>
<% } %>案例:
/*
需求:
通过 isLogin 决定最终的输出内容
true 输出 <span>欢迎回来</span>
false 输出 <button>登录</button> <button>注册</button>
*/
const ejs = require("ejs");
const fs = require("fs");
// 变量
let isLogin = true;
// 原生 JS
if (isLogin) {
console.log("<span>欢迎回来</span>");
} else {
console.log("<button>登录</button> <button>注册</button>");
}
// ejs
let html = fs.readFileSync("./03_条件渲染.ejs").toString();
let result = ejs.render(html, { isLogin });
console.log(result);ejs
<% if(isLogin) {%>
<span>欢迎回来</span>
<% }else{ %>
<button>登录</button> <button>注册</button>
<% } %>8.5 在 Express 中使用ejs
// 导入express
const express = require("express");
// 导入path
const path = require("path");
// 创建应用对象
const app = express();
// 1.设置模板引擎
app.set("view engine", "ejs");
// 2.设置模板文件的存放位置 模板文件:具有模板语法内容的文件
app.set("views", path.resolve(__dirname, "./views"));
// 创建路由
app.get("/home", (req, res) => {
// 3.render方法响应
// res.render('模板的文件名',{数据})
// 声明一个变量
let title = "首页";
res.render('home',{title});
});
// 监听端口,启动服务
app.listen(3000, () => {
console.log("服务启动成功,端口3000");
});4.创建模板文件
views/home.ejs
<p><%= title %></p>8.6 在 Express 项目中使用ejs
8.6.1 初始化项目并设置模板引擎
express -e niuman 指定模板引擎为ejs(express 默认模板引擎为jade)
创建一个 niuman 项目 并指定模板引擎为ejs
cd niuman && npm i
切换到项目目录 安装依赖
8.6.2 创建 ejs 文件
在 views 目录下创建 一个 ejs 文件,并添加内容
8.6.3 服务器端渲染页面
在路由的回调函数中使用 res.render() 渲染 ejs 页面,并传入参数
res.render('./views/index.ejs',{data:data})九、express-generator
通过应用生成器工具 express-generator 可以快速创建一个应用的骨架
9.1 全局安装
npm install -g express-generator9.2 可用的命令行参数
express -h
Usage: express [options] [dir]
Options:
-h, --help 输出使用方法
--version 输出版本号
-e, --ejs 添加对 ejs 模板引擎的支持
--hbs 添加对 handlebars 模板引擎的支持
--pug 添加对 pug 模板引擎的支持
-H, --hogan 添加对 hogan.js 模板引擎的支持
--no-view 创建不带视图引擎的项目
-v, --view <engine> 添加对视图引擎(view) <engine> 的支持 (ejs|hbs|hjs|jade|pug|twig|vash) (默认是 jade 模板引擎)
-c, --css <engine> 添加样式表引擎 <engine> 的支持 (less|stylus|compass|sass) (默认是普通的 css 文件)
--git 添加 .gitignore
-f, --force 强制在非空目录下创建9.3 创建一个 express 项目
在要创建项目的目录下输入:
express -e 15-generator说明:创建一个名叫 15-generator 的express项目 并添加 ejs 模板引擎支持
安装依赖包
cd 15-generator //切换到项目目录下 npm i // 安装 package.json 中的全部依赖包启动项目
npm start // 项目的入口文件为 ./bin/www
默认端口为 3000
可以修改 package.json 文件设置项目启动指令

测试
浏览器地址栏中输入:http://127.0.0.1:3000/
9.4 生成的项目结构
通过生成器创建的应用一般都有如下目录结构:
.
├── app.js
├── bin
│ └── www
├── package.json
├── public
│ ├── images
│ ├── javascripts
│ └── stylesheets
│ └── style.css
├── routes
│ ├── index.js
│ └── users.js
└── views
├── error.pug
├── index.pug
└── layout.pug
7 directories, 9 files十、文件上传
10.1查看文件上传报文
上传文件时 form 表单一定要设置 enctype="multipart/form-data" 属性
<form action="/portrait" method="post" enctype="multipart/form-data">
用户名: <input type="text" name="username" /><br />
头像: <input type="file" name="portrait" multiplu /><br /> //multiplu 上传多个文件
<hr>
<button>提交</button>
</form>文件上传请求报文
请求头
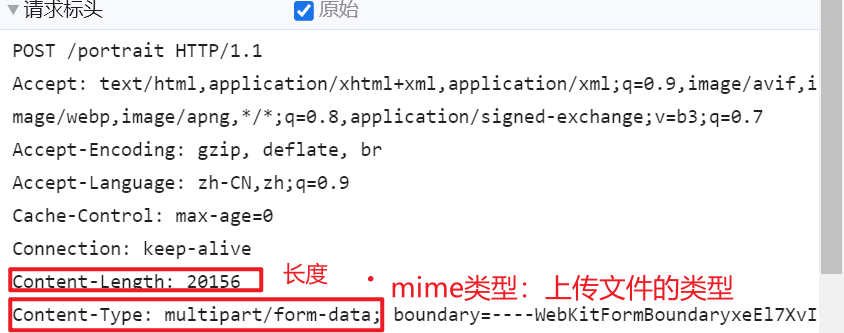
请求体
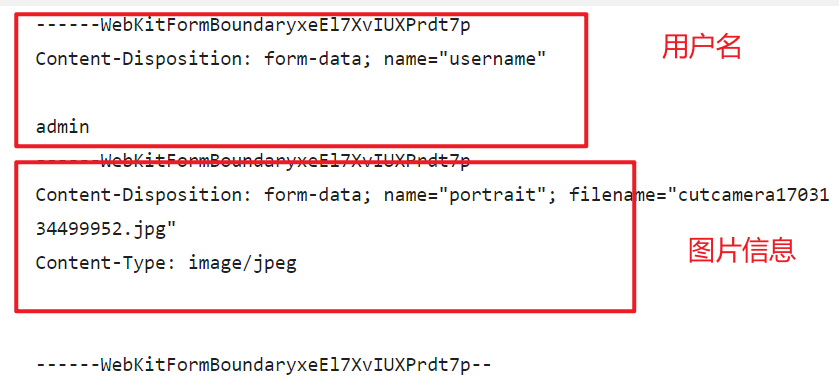
10.2 处理文件上传
可以使用 multer 或 formidable
10.2.1 安装 formidable
npm i formidable@2.1.2 需要指定版本 2.1.1
10.2.2 导入 formidable
const formidable = require("formidable");10.2.3 设置路由规则
// 导入
const formidable = require("formidable");
// 处理文件上传
router.post("/portrait", (req, res) => {
// 创建formidable对象
const form = formidable({
multiples: true,
// 设置上传文件的保存目录 /绝对路径
uploadDir: __dirname + "/../public/images",
// 保持文件后缀
keepExtensions: true,
});
// 解析请求报文
form.parse(req, (err, fields, files) => {
if (err) {
next(err);
return;
}
console.log(fields, files);
/*
fields(字段):保存 text radio checkbox select 等表单元素的值
files(文件):保存上传文件的对象
*/
/*
{"fields":{"username":"admin"},
"files":{
"portrait":{
// 上传文件大小
"size":19852,
// 存放位置
"filepath":"D:\\front_end\\NodeJS\\07 Express框架\\16-generator\\public\\images\\6954e73a81e2a40982234bf00.jpg",
// 新文件名
"newFilename":"6954e73a81e2a40982234bf00.jpg",
// mime类型
"mimetype":"image/jpeg",
// 创建时间
"mtime":"2024-02-05T03:50:25.321Z",
// 原文件名
"originalFilename":"cutcamera1703134499952.jpg"}}}
*/
//访问图片:http://127.0.0.1:3000/images/6954e73a81e2a40982234bf00.jpg
// 服务器保存该图片的访问 URL ,将其存放到数据库中方便日后访问
let url = "/images/" + files.portrait.newFilename; // 上传单个文件
// 上传多个文件
for(let item of files.portrait){
let url = 'images/' + item.newFilename;
res.write(url);
}
res.end();
});
});
module.exports = router;10.2.4 fields, files
form.parse 解析请求报文 保存在 fileds 和 files 对象中
fileds:保存text radio checkbox select 等表单元素的值
以键值对的形式保存 input组件的 name 为键名 value 为值
files:保存上传文件的信息
以键值对的形式保存
{"fields":{"username":"admin"},
"files":{
"portrait":{
// 上传文件大小
"size":19852,
// 存放位置
"filepath":"D:\\front_end\\NodeJS\\07 Express框架\\16-generator\\public\\images\\6954e73a81e2a40982234bf00.jpg",
// 新文件名
"newFilename":"6954e73a81e2a40982234bf00.jpg",
// mime类型
"mimetype":"image/jpeg",
// 创建时间
"mtime":"2024-02-05T03:50:25.321Z",
// 原文件名
"originalFilename":"cutcamera1703134499952.jpg"}
}
}10.2.5 储存上传文件的 URL
服务器保存该图片的访问 URL ,将其存放到数据库中方便日后访问,不需要保存协议域名端口,在使用 img 标签进行访问时,使用绝对路径,会自动添加当前网站的协议域名端口。
let url = "/images/" + files.portrait.newFilename; // 上传单个文件
// 上传多个文件
for(let item of files.portrait){
let url = 'images/' + item.newFilename;
res.write(url);8. MongoDB
一、简介
1.1 Mongodb 是什么
MongoDB 是一个基于分布式文件存储的数据库,官方地址 https://www.mongodb.com/
作为非关系型数据库的代表,MongoDB以键值对的形式存储数据,具有灵活的数据结构。它不需要预定义表格结构,支持分布式存储,适合存储半结构化和非结构化数据,如日志和文档。
1.2 数据库是什么
数据库(DataBase)是按照数据结构来组织、存储和管理数据的 应用程序
1.3 数据库的作用
数据库的主要作用就是 管理数据 ,对数据进行 增(c)、删(d)、改(u)、查(r)
1.4 数据库管理数据的特点
相比于纯文件管理数据,数据库管理数据有如下特点:
- 速度更快
- 扩展性更强
- 安全性更强
1.5 为什么选择 Mongodb
操作语法与 JavaScript 类似,容易上手,学习成本低
1.6 Mongdb 与 Mysql 的区别
- 数据库类型:MongoDB是非关系型数据库,也称为文档型数据库,它将数据存储为类似JSON的BSON格式文档。MySQL是一个关系型数据库,它使用表来存储数据,表中的数据以行和列的形式组织。
- 查询语言:MongoDB拥有自己独特的查询语言,其语法与JavaScript相似,支持丰富的查询表达式。而MySQL使用的是标准的SQL语句进行数据查询和管理。
- 存储方式:MongoDB采用“虚拟内存+持久化”的存储方式,热数据会被加载到内存中以实现高速读写。而MySQL根据不同的存储引擎有不同的存储方式,例如InnoDB和MyISAM。
- 适用场景:MongoDB适合处理大量的非结构化或半结构化数据,如日志记录、内容管理和博客平台等。而MySQL适用于需要复杂查询和事务支持的传统业务系统。
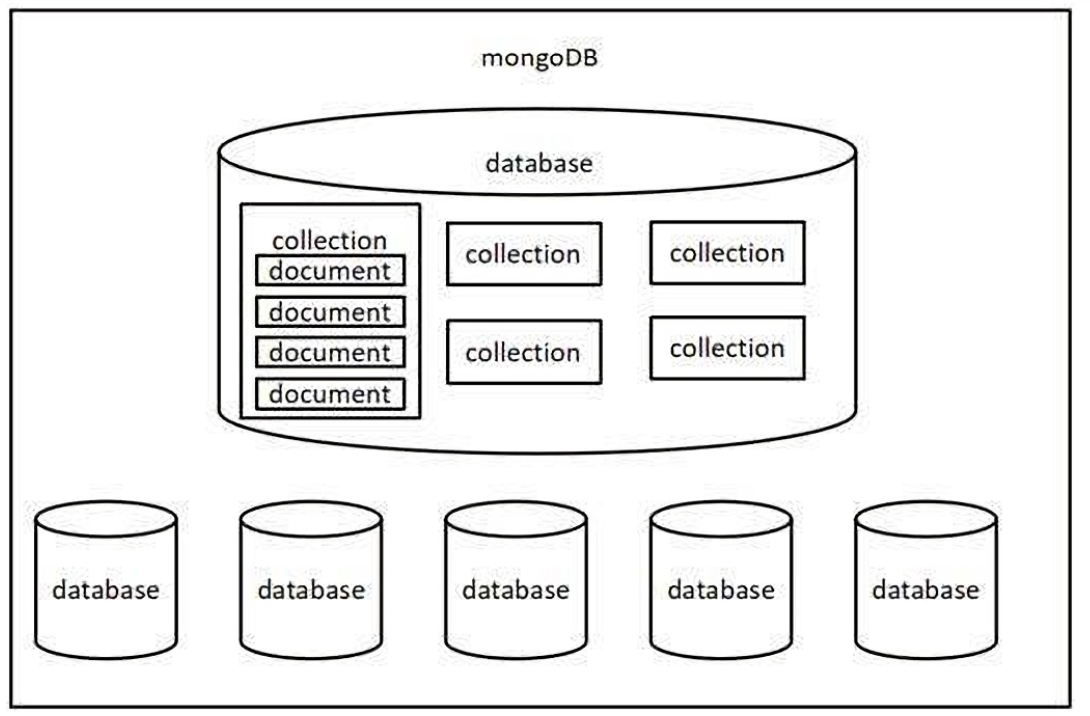
二、核心概念
Mongodb 中有三个重要概念需要掌握
- 数据库(database) 数据库是一个数据仓库,数据库服务下可以创建很多数据库,数据库中可以存 放很多集合
- 集合(collection) 集合类似于 JS 中的数组,在集合中可以存放很多文档
- 文档(document) 文档是数据库中的最小单位,类似于 JS 中的对象
{ // 一个数据库
"accounts": [ // 一个集合,集合内部存储同一种类型数据
{ // 一个文档
"id": "3-YLju5f3",
"title": "买电脑",
"time": "2023-02-08",
"type": "-1",
"account": "5500",
"remarks": "为了上网课"
},
{
"id": "mRQiD4s3K",
"title": "发工资",
"time": "2023-02-19",
"type": "1",
"account": "4396",
"remarks": "终于发工资啦!~~"
}
],
"users": [
{
"id": 2,
"name": "lisi",
"age": 20
},
{
"id": 3,
"name": "wangwu",
"age": 22
}
]
}大家可以通过 JSON 文件来理解 Mongodb 中的概念
一个 JSON 文件 好比是一个 数据库 ,一个 Mongodb 服务下可以有 N 个数据库
JSON 文件中的 一级属性的数组值 好比是 集合
数组中的对象好比是 文档
对象中的属性有时也称之为 字段
一般情况下
- 一个项目使用一个数据库
- 一个集合会存储同一种类型的数据
三、下载安装与启动
下载地址: https://www.mongodb.com/try/download/community
建议选择 zip 类型, 通用性更强(若采用 msi 的安装方式则不用以下步骤,在服务中可以开启和终止服务)
配置步骤如下:
1> 将压缩包移动到 C:\Program Files 下,然后解压
2> 创建 C:\data\db 目录,mongodb 会将数据默认保存在这个文件夹
3> 以 mongodb 中 bin 目录作为工作目录,启动命令行
4> 运行命令 mongod
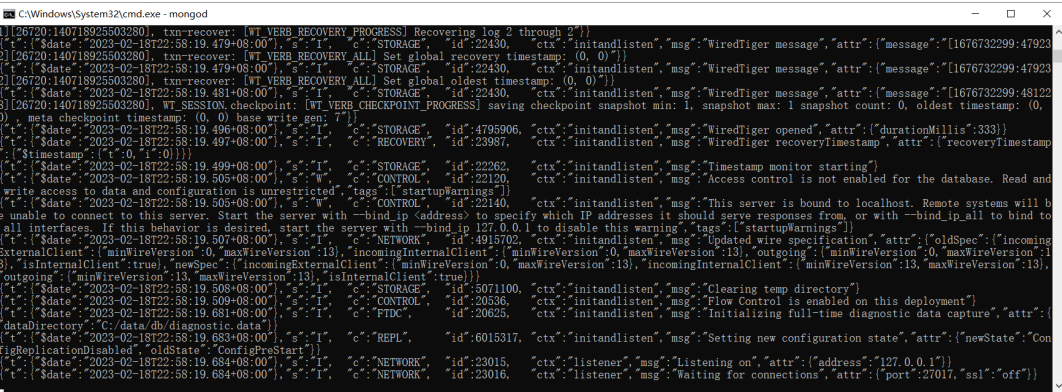
看到最后的 waiting for connections 则表明服务 已经启动成功
然后可以使用 mongo 命令连接本机的 mongodb 服务
注意:
- 为了方便后续方便使用 mongod 命令,可以将 bin 目录配置到环境变量 Path 中
- 千万不要选中服务端窗口的内容 ,选中会停止服务,可以 敲回车 取消选中
- MongoDB的默认端口为 27017
mongod:启动 MongoDB 服务 Ctrl + c :终止服务
mongo :连接本机的 mongoDB 服务
四、命令行交互
命令行交互一般是学习数据库的第一步,不过这些命令在后续用的比较少,所以大家了解即可
4.1 数据库命令
显示所有的数据库
show dbs切换到指定的数据库,如果数据库不存在会自动创建数据库
use 数据库名显示当前所在的数据库
db删除当前数据库
use 库名 db.dropDatabase()
4.2 集合命令
创建集合
db.createCollection('集合名称')显示当前数据库中的所有集合
show collections删除某个集合
db.集合名.drop()重命名集合
db.集合名.renameCollection('newName')
4.3 文档命令
插入文档
db.集合名.insert(文档对象) db.users.insert({ name:'小明',age:10}))查询文档
db.集合名.find(查询条件) db.users.find() // 查询全部 db.user.find({name: '小明'}) // 查询name为小明的文档_id 是 mongodb 自动生成的唯一编号,用来唯一标识文档
更新文档
db.集合名.update(查询条件,新的文档) db.users.update({name:'李四'},{age:20}) // 替换全部文档内容为 age:20 db.users.update({name:'张三'},{$set:{age:19}}) // 只更新 age 属性的值删除文档
db.集合名.remove(查询条件) db.user.remove({name:'李四'}) //删除掉name为李四的文档
4.4 应用场景
4.4.1 新增
- 用户注册
- 发布视频
- 发布商品
- 发朋友圈
- 发评论
- 发微博
- 发弹幕
- .......
4.4.2 删除
- 删除评论
- 删除商品
- 删除文章
- 删除视频
- 删除微博
- ......
4.4.3 更新
- 更新个人信息
- 修改商品价格
- 修改文章内容
- ......
4.4.4 查询
- 商品列表
- 视频列表
- 朋友圈列表
- 微博列表
- 搜索功能
- ......
五、Mongoose基础
5.1 介绍
Mongoose 是一个对象文档模型库,官网 http://www.mongoosejs.net/
5.2 作用
方便使用代码操作 mongodb 数据库
5.3 使用流程
5.3.1使用 mongoose 连接数据库
创建 package.json
npm init安装 mongoose 依赖包
npm i mongoose导入 mongoose
jsconst mongoose = require('mongoose')连接 mongodb数据库
jsmongoose.connection('mongodb://127.0.0.1:27017/bilibili') // 连接bilibili数据库设置回调
js// 设置连接成功的回调 once:事件回调函数只执行一次 mongoose.connection.once("open", () => { console.log("连接成功"); }); // 设置连接失败的回调 mongoose.connection.on("err", () => { console.log("连接失败"); }); // 设置连接关闭的回调 mongoose.connection.on("close", () => { console.log("连接关闭"); }); // 关闭 mongodb 的连接 setTimeout(() => { mongoose.disconnect(); }, 2000);在命令行启动 mongodb 服务
5.3.2 mongoose 插入文档
在 open 事件中 插入文档
创建文档的结构对象 Schema:结构
设置集合中文档的属性和属性值的类型
jslet BookSchema = new mongoose.Schema({ name: Streing, author: String, price: Number });创建模型对象 对文档操作进行封装
jslet BookModel = mongoose.model('books',BookSchema); // books 操作的集合名称 bookSchema 文档的结构对象新增文档对象
jsBookModel.create({ // BookModel.create() 返回一个Promise对象 name: '西游记', author: '吴承恩', price:'19.9' }.then((data)=>{ console.log(data); // 新增的文档对象 // 关闭数据库连接,在实际开发中该步骤一般不会使用 mongoose.disconnect(); }).catch((err)=>{ console.log(err); }))
5.4 字段类型
文档结构可选的常用字段类型列表

let BookSchema = new mongoose.Schema({
name: String,
author: String, // 字符串类型
price: Number, // 数字类型
is_hot: Boolean, // boolean类型
tags: Array, // 数组类型
pub_time:Date, // 日期类型
test:mongoose.Schema.Types.Mixed // 任意类型
});5.5 字段值验证
Mongoose 有一些内建验证器,可以对字段值进行验证
5.5.1 必填项
文档插入数据库时,该字段必须有值,才能插入成功
let BookSchema = new mongoose.Schema({
title: {
type: String, // 字段类型
required: true // 设置必填项
}
...
})5.5.2 默认值
当未该该字段设置值是,自动设置为默认值
autho: {
type: String, // 字段类型
default: '佚名' // 设置默认值
}5.5.3 枚举值
设置的值必须是数组中的其中一个
style: {
type: String,
enum: ['小说','漫画']
}5.5.4 唯一值
设置某一字段的值为唯一值,不能重复
username: {
type: String, // 字段类型
required: true, // 必填
unique: true // 唯一值
}注意:
unique 需要 重建集合 才能有效果
永远不要相信用户的输入,用进行谨慎检查
5.6 CURD(增删改查)
数据库的基本操作包括四个,增加(create),删除(delete),修改(update),查(read)
5.6.1 增加文档
插入一条
BookModel.create({文档对象}).then().catch()
BookModel.create(
{
name: "西游记",
author: "吴承恩",
price: 19.9,
is_hot: true,,
},
function (err, data) {
//错误
console.log(err);
//插入后的数据对象
console.log(data);
}
);在mongodb 6以上的版本 create()返回的是一个Promise 使用 .then() .catch()接收处理
BookModel.create({
name: "西游记",
author: "吴承恩",
price: 19.9,
is_hot: true,
}).then((data)=>{
console.log("新增成功");
}).catch((err)=>{
console.log("新增失败");
})批量插入
BookModel.insertMany([ {对象文档},{} ..]}.then().catch()
//1.引入mongoose
const mongoose = require("mongoose");
//2.连接 mongodb 服务 数据库的名称
mongoose.connect("mongodb://127.0.0.1:27017/bilibili");
//3.设置回调
// 设置连接成功的回调 once 一次 事件回调函数只执行一次
mongoose.connection.once("open", () => {
// 4.创建文档的结构对象
//设置集合中文档的属性以及属性值的类型
let BookSchema = new mongoose.Schema({
name: String,
author: String,
price: Number,
is_hot: Boolean,
});
// 5.创建模型对象 对文档操作的封装对象 mongoose 会自动将集合名变为负数形式
let BookModel = mongoose.model("novel", BookSchema);
//6.批量新增数据
BookModel.insertMany(
[
{
name: "西游记",
author: "吴承恩",
price: 19.9,
is_hot: true,
},
{
name: "大魏能臣",
author: "黑男爵",
price: 9.9,
is_hot: false,
},
{
name: "独游",
author: "酒精过敏",
price: 15,
is_hot: false,
},
{
name: "大泼猴",
author: "甲鱼不是龟",
price: 26,
is_hot: false,
},
{
name: "在细雨中呼喊",
author: "余华",
price: 25,
is_hot: true,
},
]
).then((data)=>{
console.log("新增成功");
mongoose.disconnect(); // 关闭数据库连接
}).catch((err)=>{
console.log("新增失败");
});
});
// 设置连接错误的回调
mongoose.connection.on("error", () => {
console.log("连接失败");
});
//设置连接关闭的回调
mongoose.connection.on("close", () => {
console.log("连接关闭");
});5.6.2 删除文档
删除一条数据
BookModel.deleteOne({ 条件 }).then().catch()
BookModel.deleteOne({ _id: "65c203189608c74660361a45" })
.then((data) => {
console.log("删除成功", data);
})
.catch((err) => {
console.log("删除失败", err);
});批量删除
BookModel.deleteMany({ 条件 }).then().catch()
BookModel.deleteMany({ is_hot: false })
.then((data) => {
console.log("删除成功", data);
//{ acknowledged: true, deletedCount: 9 } data返回删除信息条数
})
.catch((err) => {
console.log("删除失败", err);
});5.6.3 更新文档
更新一条数据
BookModel.updateOne({ 条件 }, { 更新内容 }.then().catch()
// 更新 name 为红楼梦的一条数据 将其价格改为 9.9
BookModel.updateOne({ name: "红楼梦" }, { price: 9.9 })
.then((data) => {
console.log("价格修改成功", data);
})
.catch((err) => {
console.log("更新失败", err);
});批量更新数据
BookModel.updateMany({ 条件 }, { 更新内容 }).then().catch()
// 更新 作者为余华的全部数据,设置其 is_hot 属性为 false
BookModel.updateMany({ author: "余华" }, { is_hot: false })
.then((data) => {
console.log("更新成功", data);
mongoose.disconnect();
})
.catch((err) => {
console.log("更新失败",err);
});5.6.4 查询文档
查询一条数据
BookModel.findOne({ 条件 }).then().catch()
BookModel.findById(" id ").then().catch()
// 查询name为狂飙的一条数据
BookModel.findOne({ name: "狂飙" })
.then((data) => {
console.log("查询成功", data);
mongoose.disconnect();
})
.catch((err) => {
console.log("查询失败", err);
});
// 根据 id 查询一条数据
BookModel.findById("65c203189608c74660361a37")
.then((data) => {
console.log("查询成功", data);
mongoose.disconnect();
})
.catch((err) => {
console.log("查询失败", err);
});批量查询数据
BookModel.find( [{ 条件 }] ).then().catch()
// 查询作者是余华的全部数据
BookModel.find({ author: "余华" })
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});
// 查询全部数据
BookModel.find()
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});5.7 条件控制
5.7.1 运算符
在 mongodb 不能 > < >= <= !== 等运算符,需要使用替代符号
- > 使用 $gt
- < 使用 $lt
>=使用 $gte- <= 使用 $lte
- !== 使用 $ne
db.students.find({id:{$gt:3}}); //id号比3大的所有的记录
// 将价格小于20的数据查询出来
BookModel.find({ price: {$lt:20} })
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});5.7.2 逻辑运算
$or 逻辑或的情况
db.students.find({$or:[{age:18},{age:24}]}); // 查询年龄为18或24
// 查询 曹雪芹或余华 的书
BookModel.find({ $or: [{ author: "曹雪芹" }, { author: "余华" }] })
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});$and 逻辑与的情况
db.students.find({$and: [{age: {$lt:20}}, {age: {$gt: 15}}]});
// 查询 价格大于30且小于70的数据
BookModel.find({ $and: [{ price: { $gt: 30 } }, { price: { $lt: 70 } }] })
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});5.7.3 正则匹配
条件中可以直接使用 JS 的正则语法,通过正则可以进行模糊查询
// 正则表达式,搜索数据名称中带有 三 的书籍
BookModel.find({ name: /三/ })...
BookModel.find({ name: new RegExp("三") })... // regExp 中可以设置变量
db.students.find({name:/imissyou/});5.8 个性化读取
5.8.1 字段筛选
BookModel.find().select({ 显示的字段: 1, 不显示的字段: 0 })
将要查询的字段的值设为1,不需要的设置为0或不设置
// 设置字段 只查询 name和author字段
// 将要查询的字段的值设为1,不需要的设置为0或不设置
BookModel.find()
.select({ name: 1, author: 1 })
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});5.8.2 数据排序
BookModel.find().sort({ 要排序的字段: 1 })
1:升序,-1:降序
// 数据排序 按价格进行升序排列,只显示价格和名称
BookModel.find()
.select({ name: 1, price: 1 ,_id:0})
.sort({ price: 1 }) // 1:升序 -1:降序
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});5.8.3 数据截取
skip(n) 跳过n条数据,取后面的数据
limit(n) 限定每次只取n条数据
// 按价格从高到低排序,取第4到第6条数据
BookModel.find()
.select({ name: 1, price: 1, _id: 0 })
.sort({ price: -1 })
.skip(3) // 跳过 3 条数据
.limit(3) // 限定只取3条数据
.then((data) => {
console.log("查询成功", data);
})
.catch((err) => {
console.log("查询失败", err);
});可以将大量数据截取分开从数据库中获取,减轻服务器和客户端压力
六、Mongoose模块化
将重复使用的代码进行封装,便于复用
创建配置文件
创建一个 config 文件夹,在内部创建一个 config.js 文件
js// 配置文件 module.exports={ // 暴露一个对象 DBHOST:'127.0.0.1', // 设置主机名 DBPORT:27017, // 设置端口号 DBNAME:'bilibili' // 设置要操作的数据库的名称 }创建数据库连接文件 db.js
暴露一个函数,接收连接成功和失败的回调函数
js/* @param{*} success 数据库连接成功的回调 @param{*} error 数据库连接失败的回调 */ // 暴露一个函数 module.exports = function (success, error) { // 当未传递错误回调时,设置error的默认值 if (typeof error !== "function") { error = () => { console.log("连接失败"); }; } // 导入mongoose const mongoose = require("mongoose"); // 导入配置文件 const { DBHOST, DBPORT, DBNAME } = require("../config/config"); // 连接 mongodb 数据库 mongoose.connect(`mongodb://${DBHOST}:${DBPORT}/${DBNAME}`); // 设置回调 // 设置连接成功的回调 once:事件回调函数只执行一次 mongoose.connection.once("open", () => { success(); //连接成功的回调 }); // 设置连接失败的回调 mongoose.connection.on("err", () => { error(); }); // 设置连接关闭的回调 mongoose.connection.on("close", () => { console.log("连接关闭"); }); };创建模型对象文件
创建 models 文件夹在内部创建 BookModels 模型对象
js// 导入 mongoose const mongoose = require("mongoose"); // 创建文档的结构对象 Schema:结构 let BookSchema = new mongoose.Schema({ name: String, author: String, price: Number, }); // 创建模型对象 对文档操作的封装对象 let BookModel = mongoose.model("books", BookSchema); // 暴露模型对象 module.exports = BookModel;导入 db BookModels 操作模型对象
js// 导入 db 文件 const db = require("./db/db"); // db为一个函数,有两个参数 // 导入 BookModel 文件 const BookModel = require("./models/BoookModel"); // BookModel 为模型对象 // 导入 mongoose const mongoose = require('mongoose') // 调用函数 db( () => { // 连接成功回调 console.log("连接成功"); // 新增文档对象 BookModel.create({ name: "水浒传", author: "施耐庵", price: 12.9, }) .then((data) => { console.log('插入成功'); // 关闭数据库连接 (项目运行过程中,不会添加该代码) mongoose.disconnect(); }) .catch((err) => { console.log('插入失败'); }); }, () => { // 连接失败回调 console.log("连接失败"); } );
七、图形化管理工具
我们可以使用图形化的管理工具来对 Mongodb 进行交互,这里演示两个图形化工具
Navicat 收费 https://www.navicat.com.cn/
9.接口
一、简介
1.1 接口是什么
接口是 前后端通信的桥梁
简单理解:一个接口就是 服务中的一个路由规则 ,根据请求响应结果
接口的英文单词是 API (Application Program Interface),所以有时也称之为 API 接口
这里的接口指的是『数据接口』, 与编程语言(Java,Go 等)中的接口语法不同
API接口 响应返回一个JSON格式的内容,再由前端工程师对数据进行渲染
前端通过接口获取/上传数据,后端向前端返回 json 格式的数据,前端再对数据进行处理(前后端分离),不再直接由后端渲染页面(服务器端渲染)。
1.2 接口的作用
实现 前后端通信
1.3 接口的开发与调用
大多数接口都是由 后端工程师 开发的, 开发语言不限
一般情况下接口都是由 前端工程师 调用的,但有时 后端工程师也会调用接口 ,比如短信接口,支付接口 等
1.4 接口的组成
一个接口一般由如下几个部分组成
- 请求方法
- 接口地址(URL)
- 请求参数
- 响应结果
一个接口示例 https://www.free-api.com/doc/325




二、RESTful API
RESTful(舒适的) API 是一种特殊风格的接口,主要特点有如下几个:
- URL 中的路径表示 资源 ,路径中不能有 动词 ,例如 create , delete , update 等这些都不能有
- 操作资源要与 HTTP 请求方法 对应 (不同的操作对应不同的请求)
- 操作结果要与 HTTP 响应状态码 对应 (成功:200,不存在:404)
规则示例:
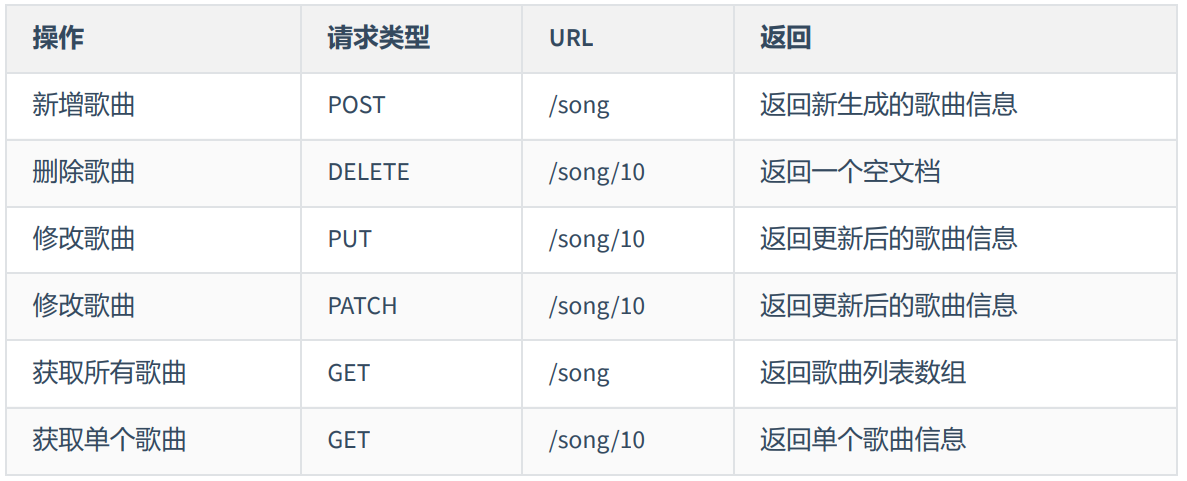
扩展阅读:https://www.ruanyifeng.com/blog/2014/05/restful_api.html
tips:
/song/10 10为id值
PUT:替换全部内容更新为新内容
PATCH:只更新同名字段内容
三、json-server
json-server 本身是一个由 JS 编写的工具包,可以快速搭建 RESTful API 服务
通过在 db.json 中添加json格式的数据,然后生成对应 json 数据的 API
用来临时搭建一个接口服务,用于前端mock API
官方地址: https://github.com/typicode/json-server
操作步骤:
- 全局安装 json-server
npm i -g json-server- 创建 JSON 文件(db.json),编写基本结构
{
"song": [
{ "id": 1, "name": "干杯", "singer": "五月天" },
{ "id": 2, "name": "当", "singer": "动力火车" },
{ "id": 3, "name": "不能说的秘密", "singer": "周杰伦" }
],
"user": [{}]
}- 以 JSON 文件所在文件夹作为工作目录 ,执行如下命令
json-server --watch db.json创建两个接口服务
默认监听端口为 3000
四、接口测试工具
介绍几个接口测试工具
4.1 apipost
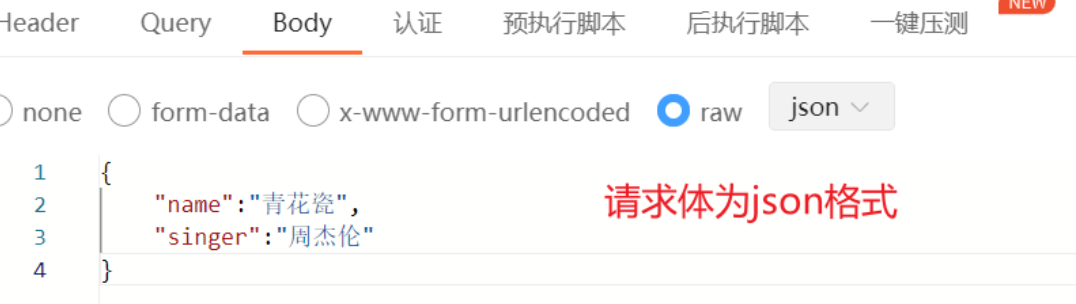
按照以下的实例进行测试(RESTful API)
/song/10 10为id值
PUT:替换全部内容更新为新内容
PATCH:只更新同名字段内容
4.1.1Apipostost公共参数
为多个请求设置相同的请求头
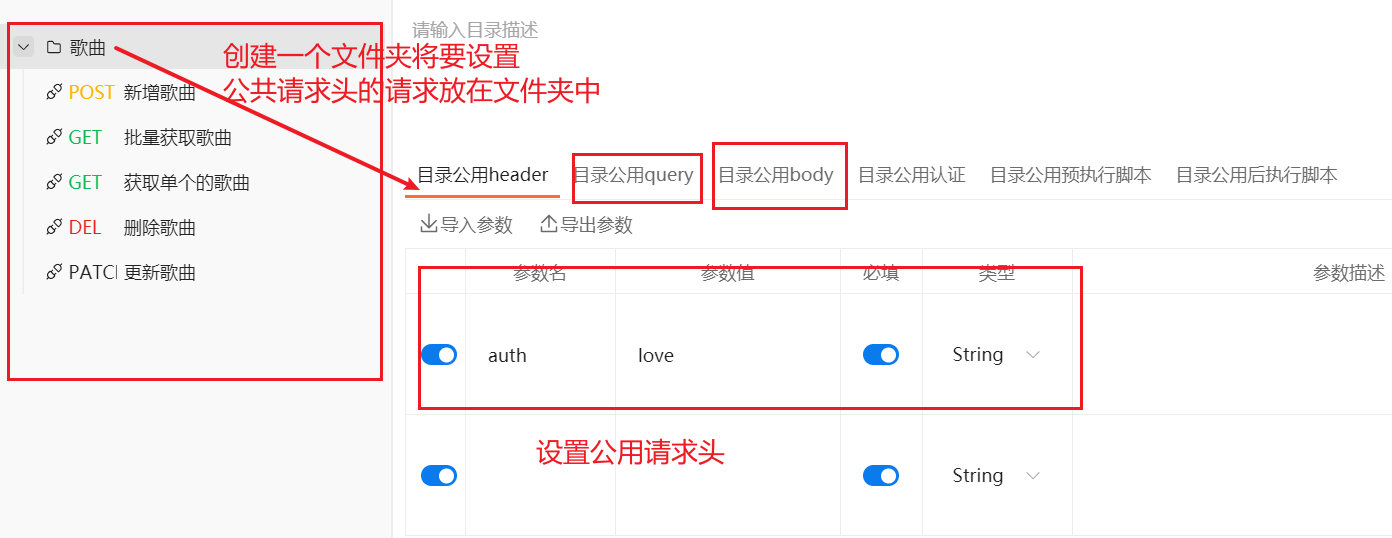
4.1.2Apipostost接口文档
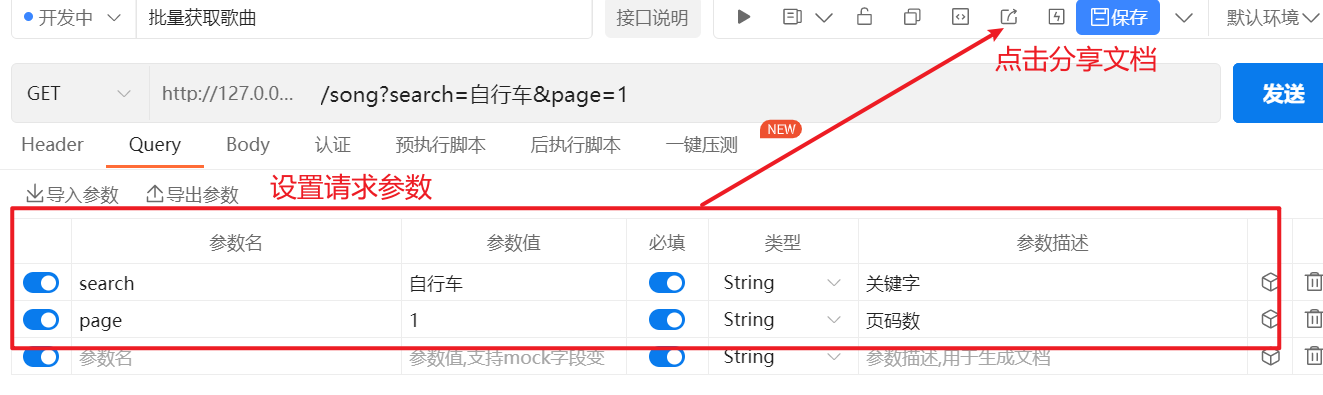
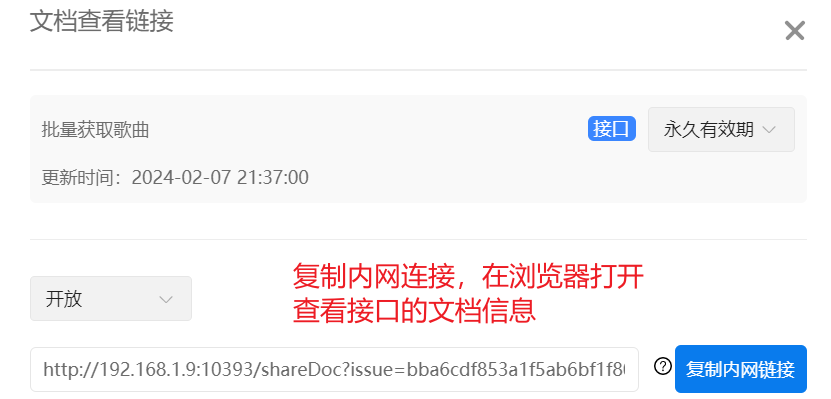
在项目全部开发完毕后,点击分享项目,复制url 在浏览器查看全部接口文
4.2 apifox
4.3 postman
10.会话控制
一、介绍
HTTP 是一种无状态的协议,它没有办法区分多次的请求是否来自于同一个客户端, 无法区分用户 而产品中又大量存在的这样的需求,所以我们需要通过 会话控制 来解决该问题 常见的会话控制技术有三种:
- cookie
- session
- token
用于向服务器传递用户信息
二、cookie
2.1cookie介绍
cookie 是 HTTP 服务器发送到用户浏览器并保存在本地的一小块数据 。
cookie 是保存在浏览器端的一小块数据 。
cookie 是按照域名划分保存的。

2.2cookie的特点
浏览器向服务器发送请求时,会自动将 当前域名下 可用的 cookie 设置在请求头中,然后传递给服务器
这个请求头的名字也叫 cookie ,所以将 cookie 理解为一个 HTTP 的请求头也是可以的。
2.3 cookie 的运行流程
填写账号和密码校验身份,校验通过后下发 cookie。
浏览器将用户名和密码发给服务器,服务器识别成功后向浏览器返回cookie,存储在浏览器端。
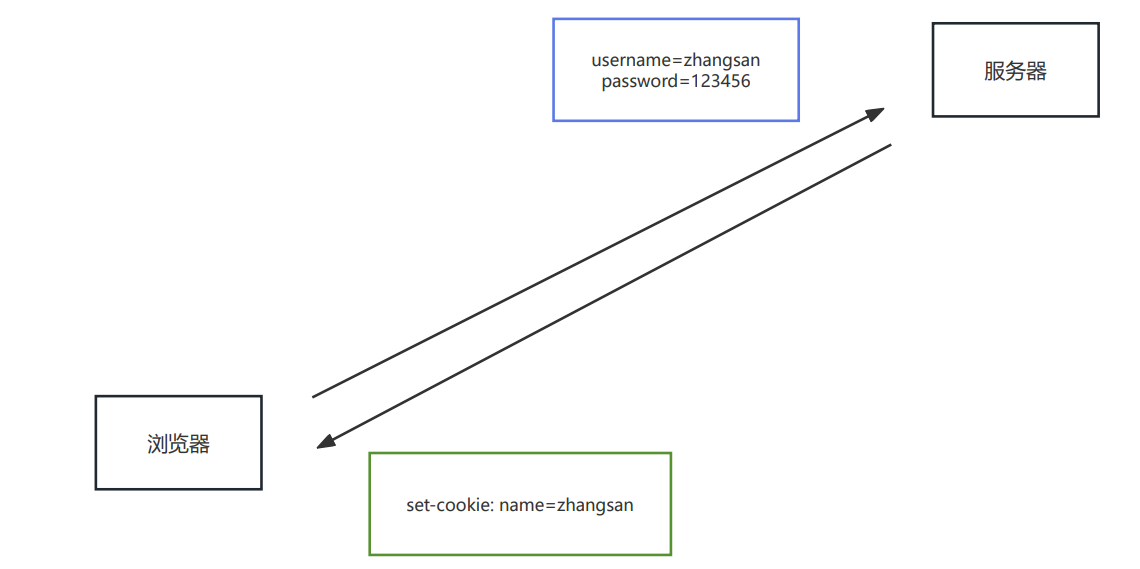
有了 cookie 之后,后续向服务器发送请求时,就会自动携带 cookie。浏览器将会识别到用户,识别到用户的登录信息等。
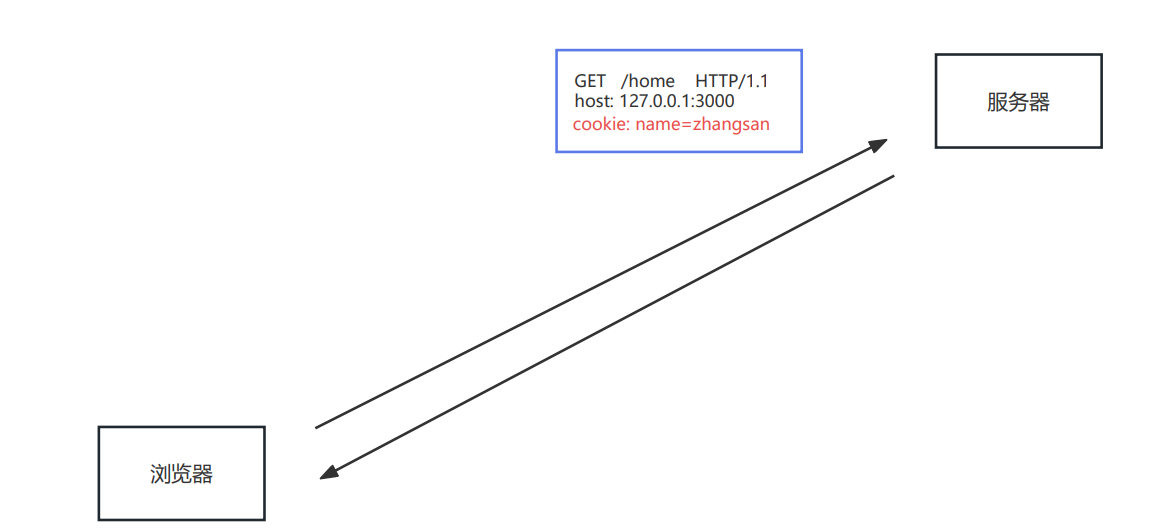
2.4 浏览器操作 cookie
浏览器对操作 cookie 的操作,使用相对较少,大家了解即可,可以在浏览器设置中操作。
禁用所有 cookie

删除 cookie

查看 cookie
2.5在Express框架中使用cookie
express 中可以使用 cookie-parser 对Cookie进行处理
使用Expess generate 生成的项目自动会配置好cookie。
2.5.1设置Cookie
res.cookie("键名",”值“[,{maxAge:60 *60 *1000}])
失效时间单位为毫秒,若不设置失效时间,则在退出浏览器时会自动销毁。
在cookie未过期时用户每次向浏览器发送/set-cookie请求时都会重新刷新cookie的有效期。所以当用户经常时用某个app时,登录一般不会过期,当长时间不使用时就会让用户重新登陆。
app.get("/set-cookie", (req, res) => {
res.cookie("name", "zhangSan"); // 会在浏览器关闭时销毁
res.cookie("name", "lisi", { maxAge: 60 * 1000 }); // 设置cookie的生命周期单位为毫秒 一分钟后过期
res.cookie("theme", "blue");// 设置多个cookie
res.send("home");
});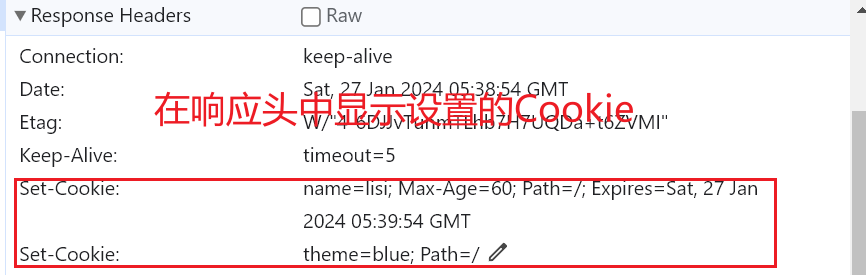
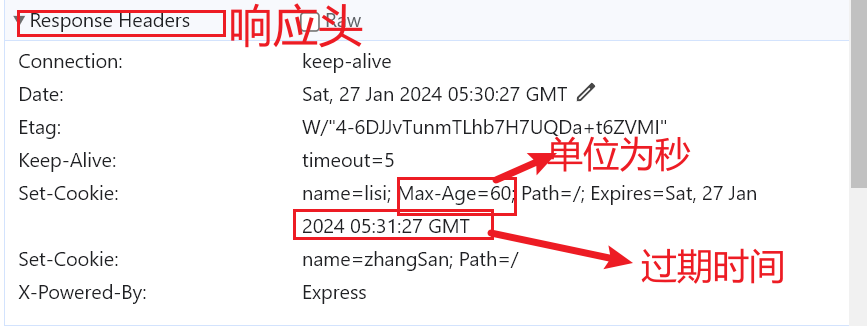
2.5.2删除Cookie
res.clearCookie("键名")
app.get("/remove-cookie", (req, res) => {
// 删除cookie中的name
res.clearCookie("name");
res.send("删除成功");
});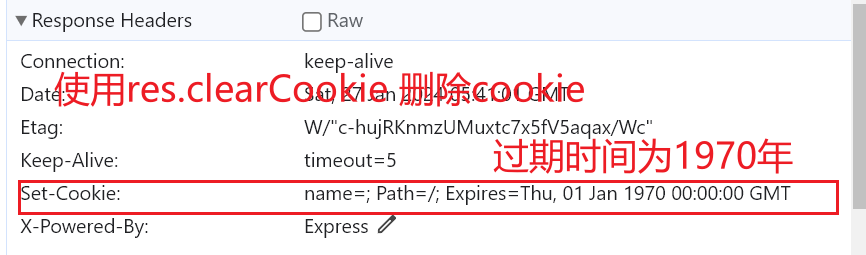
2.5.3获取Cookie
先安装cookie-parser
npm i cookie-parser
使用:
req.cookies[.键名]
const cookieParser = require('cookie-parser');
app.use(cookieParser())
// 获取cookie
app.get('/get-cookie',(req,res)=>{
//获取 全部cookie
console.log(req.cookies);
// 获取指定键名的cookie
res.send(`欢迎您${req.cookies.name}`);
})在第一次请求时无法获取到cookie,第一次请求匹配成功后,服务器将cookie发送给浏览器,浏览器将cookie保存,第二次请求时浏览器将在请求头上添加cookie。
获取到cookie信息后再与数据库中的信息进行匹配,判断用户是否存在。
2.6 nodemon
nodemon 是一个用于监视 Node.js 应用程序文件更改的工具。当检测到文件更改时,它会自动重启应用程序,从而节省了手动重启的时间。
要使用 nodemon,首先需要安装它。可以通过 npm 或 yarn 进行安装:
npm install -g nodemon 或者 yarn global add nodemon
安装完成后,可以使用 nodemon 命令代替 node 命令来运行你的应用程序。
还可以在 package.json 文件中配置 nodemon,以便在运行 npm start 或 yarn start 时自动使用 nodemon:
{
"scripts": {
"start": "nodemon app.js"
}
}这样,只需运行 npm start 或 yarn start,即可使用 nodemon 启动应用程序
三、Session
3.1session简介
session 是保存在 服务器端的一块儿数据 ,保存当前访问用户的相关信息
3.2session的作用
实现会话控制,可以识别用户的身份,快速获取当前用户的相关信息
3.3session的运行流程
填写账号和密码校验身份,校验通过后创建 session 信息 ,然后将 session_id(唯一) 的值以 cookie 形式通过响应头返回 给浏览器
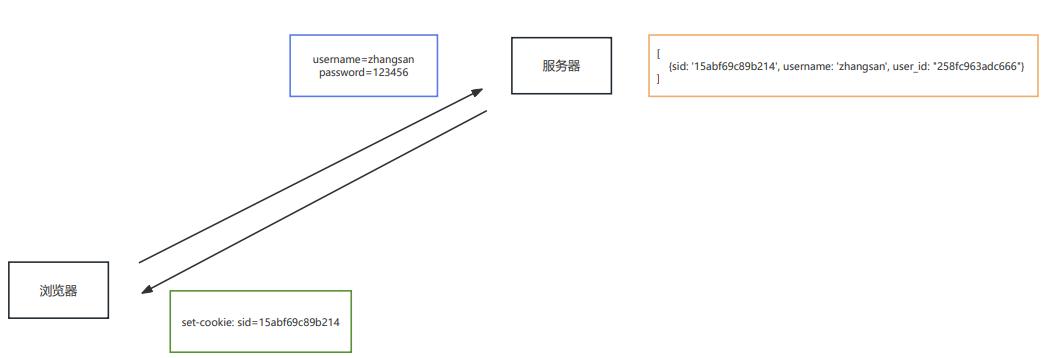
有了 cookie,下次发送请求时会自动携带 cookie,服务器通过 cookie 中的 session_id 的值确定用 户的身份
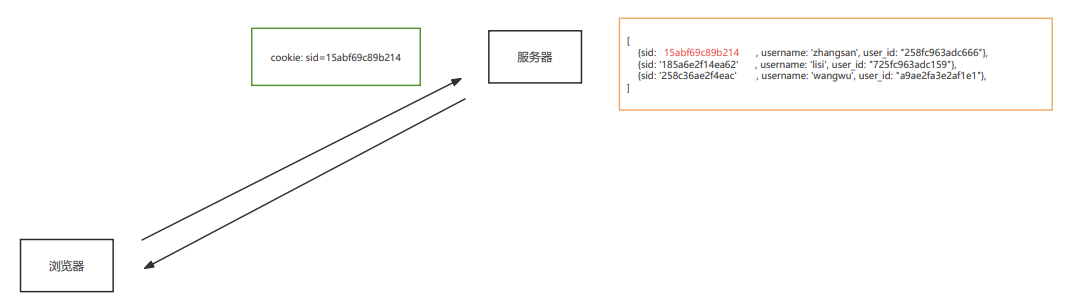
3.4在Express框架中使用session
3.4.1安装
npm i express-session connect-mongo
connect-mongo:连接mongodb 数据库将session存储在mongodb数据库中。
3.4.2引入
const session = require("express-session");
const MongoStore = require('connect-mongo');3.4.3设置session的中间件
app.use(
session({
name: "sid", //设置cookie的name,默认值是:content.sid
secret: "atguigu", //参与加密的字符串(又称签名)
saveUninitialized: false, //是否为每次请求都设置一个cookie用来存储session的is
resave: true, //设置为true表示每次请求都会重新保存session(无感刷新)
/*store: new MongoStore({
// 将session存储到mongodb数据库中
url: "mongodb://localhost:27017/session",
// 保存session的数据库名
db: "session",
// 保存session的集合名
collection: "sessions",
}),*/
store: MongoStore.create({ // 设置存储session的数据库
mongoUrl: `mongodb://${DBHOST}:${DBPORT}/${DBNAME}`,
}),
cookie: {
httpOnly: true, // 开启前端无法通过JS操作cookie
maxAge: 1000 * 60 * 60 * 24 * 30, // 设置有效期30天
},
})
);3.4.4创建session
req.session.键名= 值;
创建session设置用户的session信息并将其存储到数据库(服务器端)中,并为浏览器返回一个cookie(session_id)。
// 用户登录时创建session
app.get('/login',(req,res)=>{
if(req.query.username === 'admin' && req.query.password === 'admin'){
// 设置用户的session信息 将会被存储到数据库中
req.session.username = 'admin';
req.session.uid = '258aefcc';
// 成功响应
res.send('登录成功');
}else{
res.send('登录失败');
}
})3.4.5获取session
req.session.键名
从数据库中读取用户session信息判断是否存在用户数据,如果存在用户数据说明用户已经登录且session还未过期。当session过期后,存储在数据库/服务器的session数据会被销毁掉。
// 用户访问购物车页面时获取session判断用户是否已经登录
app.get('/cart',(req,res)=>{
// 检测session是否存在用户数据,如果存在用户数据说明用户已经登录且,session还未过期
if(req.session.username){
res.send(`欢迎${req.session.username},您已登录`);
}else{
res.send("您还未登录")
}
})3.4.5销毁session
req.session.destroy(callback)
将数据库/服务器中的session销毁。
// 用户退出登录时销毁session
app.get("/logout",(req,res)=>{
req.session.destroy(()=>{
res.send("您已退出登录")
})
})四、session 和 cookie 的区别
cookie 和 session 的区别主要有如下几点:
- 存储的位置
- cookie:浏览器端
- session:服务端
- 安全性
- cookie 是以明文的方式存放在客户端的,安全性相对较低
- session 存放于服务器中,所以安全性 相对 较好
- 网络传输量
- cookie 设置内容过多会增大报文体积, 会影响传输效率
- session 数据存储在服务器,只是通过 cookie 传递 id,所以不影响传输效率
- 存储限制
- 浏览器限制单个 cookie 保存的数据不能超过 4K ,且单个域名下的存储数量也有限制
- session 数据存储在服务器中,所以没有这些限制
五、token
5.1什么是token
token 是服务端生成并返回给 HTTP 客户端的一串加密字符串, token 中保存着 用户信息
5.2 token 的作用
实现会话控制,可以识别用户的身份,
token主要用于移动端 APP,小程序、session/cookie 重要用于网页端。
5.3 token 的工作流程
填写账号和密码校验身份,校验通过后响应 token,token 一般是在响应体中返回给客户端的
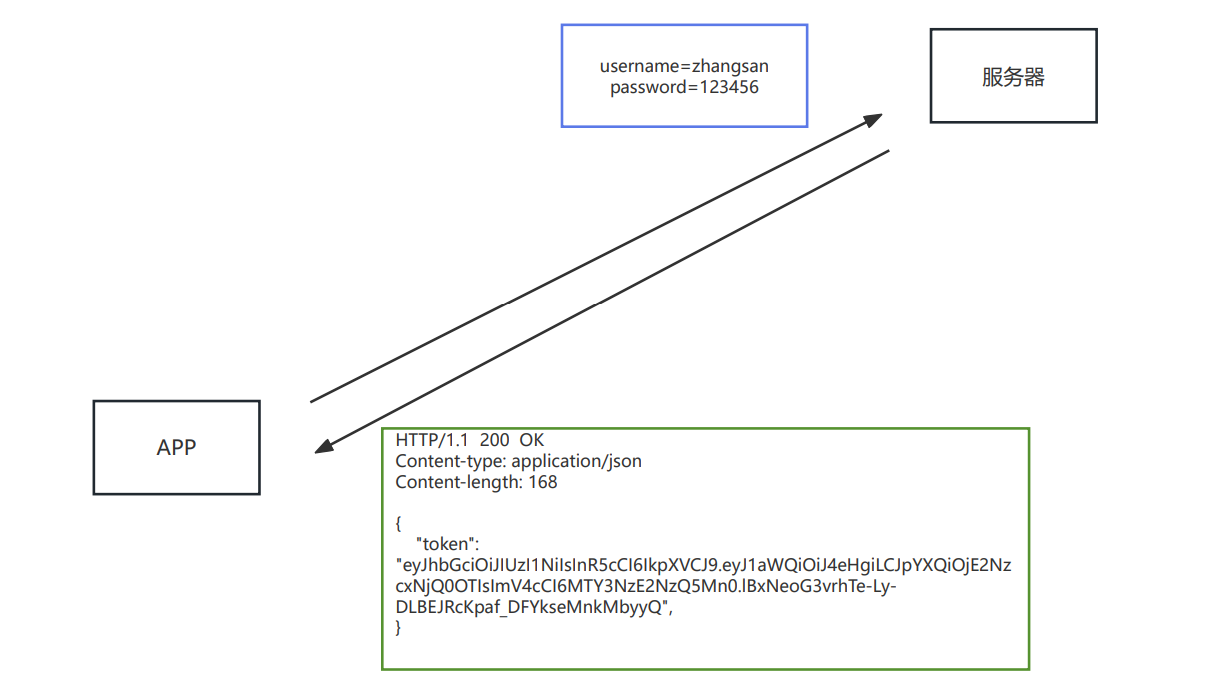
后续发送请求时,需要手动将 token 添加在请求报文中,一般是放在请求头中
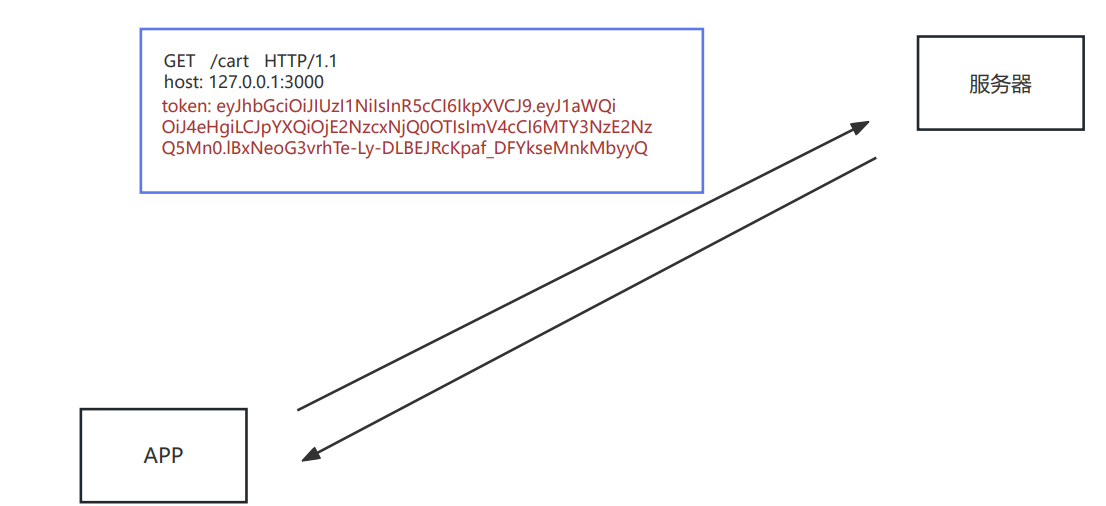
5.4 token 的特点
- 服务端压力更小
- 数据存储在客户端
- 相对更安全
- 数据加密
- 可以避免 CSRF(跨站请求伪造)
- 扩展性更强
- 服务间可以共享
- 增加服务节点更简单
5.5 JWT
JWT(JSON Web Token )是目前最流行的跨域认证解决方案,可用于基于 token 的身份验证
JWT 使 token 的生成与校验更规范
我们可以使用 jsonwebtoken 包 来操作 token
5.5.1安装jsonwebtoken并导入
cnpm i jsonwebtoken
const jwt = require('jsonwebtoken');5.2.2创建(生成token)
当客户端将信息发送到服务器,服务端校验成功后,生成token并返回客户端
let token = jwt.sign(用户数据,加密字符串,配置对象)
let token = jwt.sign(
{
username: "张三",
},
"fhjksadh", // 加密字符串
{
expiresIn: 60, // 设置生命周期,单位为秒
}
);
console.log(token);
//eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6IuW8oOS4iSIsImlhdCI6MTcwNjM1NjcwOCwiZXhwIjoxNzA2MzU2NzY4fQ.x5BDKVKmPPrSD6WyZRomDbNOudfn3FHMOu3304L7ZgI5.5.3校验token
当客户端再次发送token时,服务器端将进行token验证,验证成功后获取用户数据。
jwt.verify(token值, "加密字符串", (err, data) =>{})
jwt.verify(t, "fhjksadh", (err, data) => {
if (err) {
console.log("校验失败");// token过期或不正确
return;
} else {
console.log(data); //{ username: '张三', iat: 1706356880, exp: 1706356940 }
}
});11.连接MySQL
1、安装mysql模块
npm i mysql2、连接mysql
在项目根目录下创建 db/db.js 用于连接mysql数据库
// 引入mysql模块
const mysql = require("mysql");
// 创建连接mysql数据库的对象
let db = mysql.createConnection({
host: "localhost", // 主机名
user: "root", // mysq用户名
password: "root", // 密码
database: "niuman", // 数据库名
});
// 建立数据连接
conn.connect((err) => {
if (err) {
console.log("数据库连接失败");
} else {
console.log("数据库连接成功");
}
});
// 将连接数据库模块暴露出去,在其它文件中需要连接数据库时,直接引入该模块减少代码量
module.exports = db;3、数据库连接测试
在routes目录下的index.js文件中引入db.js文件,进行测试(数据库是否连接成功)
let db = require('../public/db/db'); 启动项目:npm run start

4、操作数据库
router.get("/", function (req, res, next) {
db.query("sql语句",(err,data)=>{
if(err){
// sql语句执行失败
}
res.json({
code:"200"
data:data
})
})
}5、示例
var express = require("express");
var router = express.Router();
const db = require("../db/db.js");
router.get("/list", function (req, res, next) {
db.query(`select * from user`, (err, data) => {
if (err)
return res.json({
code: 500,
data: err,
msg: "error",
});
res.json({
code: 200,
data: data,
msg: "success",
});
});
});
router.post("/login", function (req, res) {
const { username, password } = req.body;
db.query(
`select * from user where name='${username}' and password='${password}'`,
(err, data) => {
if (err)
return res.json({
code: 500,
data: err,
msg: "error",
});
if (data.length > 0)
return res.json({
code: 200,
data: data,
msg: "登录成功",
});
db.query(
`insert into user(name,password) values('${username}','${password}')`,
(err, data) => {
if (err)
return res.json({
code: 500,
data: err,
msg: "error",
});
res.json({
code: 201,
data: data,
msg: "注册成功",
token: "token",
});
}
);
}
);
});
module.exports = router;